WIP: Pass on color_attribute metadata through instancing, only for mesh #107066
No reviewers
Labels
No Label
Interest
Alembic
Interest
Animation & Rigging
Interest
Asset Browser
Interest
Asset Browser Project Overview
Interest
Audio
Interest
Automated Testing
Interest
Blender Asset Bundle
Interest
BlendFile
Interest
Collada
Interest
Compatibility
Interest
Compositing
Interest
Core
Interest
Cycles
Interest
Dependency Graph
Interest
Development Management
Interest
EEVEE
Interest
EEVEE & Viewport
Interest
Freestyle
Interest
Geometry Nodes
Interest
Grease Pencil
Interest
ID Management
Interest
Images & Movies
Interest
Import Export
Interest
Line Art
Interest
Masking
Interest
Metal
Interest
Modeling
Interest
Modifiers
Interest
Motion Tracking
Interest
Nodes & Physics
Interest
OpenGL
Interest
Overlay
Interest
Overrides
Interest
Performance
Interest
Physics
Interest
Pipeline, Assets & IO
Interest
Platforms, Builds & Tests
Interest
Python API
Interest
Render & Cycles
Interest
Render Pipeline
Interest
Sculpt, Paint & Texture
Interest
Text Editor
Interest
Translations
Interest
Triaging
Interest
Undo
Interest
USD
Interest
User Interface
Interest
UV Editing
Interest
VFX & Video
Interest
Video Sequencer
Interest
Virtual Reality
Interest
Vulkan
Interest
Wayland
Interest
Workbench
Interest: X11
Legacy
Blender 2.8 Project
Legacy
Milestone 1: Basic, Local Asset Browser
Legacy
OpenGL Error
Meta
Good First Issue
Meta
Papercut
Meta
Retrospective
Meta
Security
Module
Animation & Rigging
Module
Core
Module
Development Management
Module
EEVEE & Viewport
Module
Grease Pencil
Module
Modeling
Module
Nodes & Physics
Module
Pipeline, Assets & IO
Module
Platforms, Builds & Tests
Module
Python API
Module
Render & Cycles
Module
Sculpt, Paint & Texture
Module
Triaging
Module
User Interface
Module
VFX & Video
Platform
FreeBSD
Platform
Linux
Platform
macOS
Platform
Windows
Priority
High
Priority
Low
Priority
Normal
Priority
Unbreak Now!
Status
Archived
Status
Confirmed
Status
Duplicate
Status
Needs Info from Developers
Status
Needs Information from User
Status
Needs Triage
Status
Resolved
Type
Bug
Type
Design
Type
Known Issue
Type
Patch
Type
Report
Type
To Do
No Milestone
No project
No Assignees
3 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: blender/blender#107066
Loading…
Reference in New Issue
No description provided.
Delete Branch "Baardaap/blender:pass_active_color_to_instances"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Since color attributes don't use the CustomData active/render/clone index system
anymore the active status is no longer embedded in the CustomData itself.
In 3.4 and earlier if you use an
Instance on Pointsnode to instance mesh dataon the vertices of a base mesh and then realize the instances the first color attribute
in the resulting mesh (which can be inherited from the base mesh or the instances)
gets set as the active color attribute. This is useful because it allows rendering
pointcloud data in a fast way in solid mode (see #106563).
However with the named system this no longer works and the resulting mesh after realize
does not have an active color attribute (even though the attribute data itself is inherited just fine)
This patch shows one approach.
It stores the active/default color attribute from the instancer mesh on the Instances level and then uses that to set the active/default in the resulting mesh. If the instancer mesh does not have an active/default color attribute it uses the first one it encounters in the list of instanced meshes.
Questions/doubts I have:
Other possibilities:
Another approach would be to just check if there are color attributes present on the resulting mesh after a realize instances just make the first one active+default. Slightly less control, but maybe easier to implement and probably more or less equivalent to what happened in 3.4.
Yet another approach would be to build a full system of priorities and collect all this metadata in the gather phase and then use the priorities to pick the best option. I'd imagine the instancer mesh to have the highest priority. Direct mesh instances a lower one and instances in instances an even lower one. That might be slightly better than what I do in this patch (just pick the first I encounter in the list of instanced meshes) at the cost of considreably more complexity.
edit:
Another approach would be to leave the strings alone completely and if a mesh has no active/default set just always use the first one as active/default. That would have the added benefit of fixing #107206
Related thoughts
With these 2 possible future developments in mind it might be better to eventually store this metadata in some sort of easier to handle container then as bare
char *on the object data. Maybe a key-value based system?@ -215,2 +217,4 @@params,attributes_to_propagate);if (type == GEO_COMPONENT_TYPE_MESH) {const Mesh *src_mesh = ((MeshComponent *)geometry_set.get_component_for_read(type))->get_for_read();geometry_set.get_mesh_for_read()is a simpler way of writing this.Some property labels need a context to disambiguate them from others which have the same name. The only way to show the proper text currently for such properties is to override it in the UI code with a translation context, like: ```python layout.prop(obj, "area", text="Area", context=i18n_contexts.amount) ``` Python properties already store a translation context though, but this context cannot be chosen from a Python script. For instance, typing: ```python bpy.types.Scene.test_area = bpy.props.BoolProperty(name="Area") print(bpy.context.scene.bl_rna.properties['test_area'].translation_context) ``` will print `*`, the default context for Python props. This commit allows specifying a context in this manner: ```python from bpy.app.translations import contexts as i18n_contexts bpy.types.Scene.test_number_area = bpy.props.BoolProperty( name="Area", translation_context=i18n_contexts.amount ) print(bpy.context.scene.bl_rna.properties['test_number_area'].translation_context) ``` will now print `Amount` and can be translated differently from other labels. In this instance, the word for a surface area measurement, instead of a UI area. ----- This is what translated properties look like using the existing ("Area", "") and ("Area", "Amount") messages: 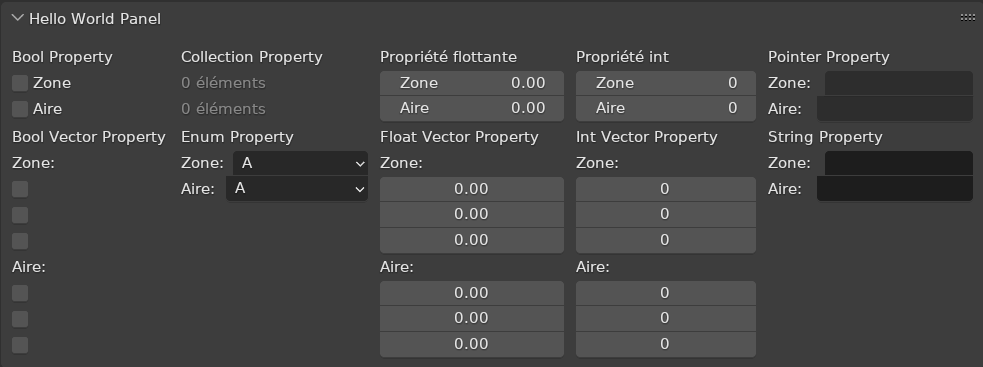 The panel can be generated with this script: [python_prop_contexts_test.py](/attachments/ab613cdc-8eba-46bc-8f3c-ad0a97e7a6e5) Pull Request: #107150The practical problem this change addresses is ability to have base flag dependent functionality in Cycles without re-setting the render on selection. This problem initially arose during the Cycles light linking project. The original review happened there: #105837 Pull Request: #108182I think the conclusion from the last module meeting was that the thing this patch does for instances should be done for joining as well. I'll try to update the patch and add join handling.
0068cd0771tof5c52ce17frebased onto blender-v3.6-release
f5c52ce17ftoc3a8457b42rebased onto blender-v3.6-release again.
I had to untangle some erroneous merges with main.
c3a8457b42to3f83adf70fWIP: Pass on color_attribute metadata through instancing, only for meshto WIP: Pass on color_attribute metadata through instancing, only for meshSeems in !117249 it has been more or less decided that active wont be set from procedural geometry?
Checkout
From your project repository, check out a new branch and test the changes.