Similar to the previous commit, this simplifies future refactoring
to change the way edges are stored, and further differentiates
single poly variables from array pointers.
Consistently use edge draw flag instead of original index to determine if an
edge should be drawn or not.
In GPU subdivision the edge original index was used for both edge optimal
display and selection mapping to coarse edges, but they are not the same.
Now match the CPU subdivision logic and use a separate edge draw flag VBO.
For cage display, match Blender 3.3 behavior more in showing/hiding of edges
in wireframe mode. That is edges without a mapping to an original edge are
always hidden when there is no distinct cage, and drawn otherwise. This is
not ideal for e.g. the bevel modifier where it will always show some edges on
corners despite all edges being hidden by the user. But we currently have
no good information to decide if these should be hidden or not, so err on
the side of showing too much as it did before.
Fie #103706: bevel modifier edges not drawn correctly
Fix#103700: optimal display can't be turned of with GPU subdivision
Fix wrong edge display with GPU subdivision preceded by other modifiers
Pull Request #105384
Intel GPUs exhibit a number of rendering artifacts.
The most substantial being incorrect resolve of reflections.
Splitting the reflections_resolve shader into two passes,
one for SSR and one for light probes ensures correct rendering
and optimal performance on this GPU.
Also resolves an artifact with ambient occlusion wherein
the pow(a, b) function causes excessive precision loss.
Using an alternative method for power calculation on these
platforms resolves the issues.
Authored by Apple: Michael Parkin-White
Ref T96261
Pull Request #105240
Metal backed requires HOST_READ texture usage flag
for irradiance grid. This was correctly in place for the
basic grid, but not for grid_prev.
Authored by Apple: Michael Parkin-White
Ref #96261
Pull Request #105312
Add overlay option for retopology, which hides the shaded mesh akin to Hidden Wire, and offsets the edit mesh overlay towards the view.
Related Task #70267
Pull Request #104599
Increase the buffer sizes used for `BLI_str_format_uint64_grouped` to
prevent overflow on strings representing numbers within the uint64
range. Also creates and uses defines for all the formatted string
buffer sizes.
Pull Request #105263
With the goal of clearly differentiating between arrays and single
elements, improving consistency across Blender, and using wording
that's easier to read and say, change variable names for Mesh edges
and polygons/faces.
Common renames are the following, with some extra prefixes, etc.
- `mpoly` -> `polys`
- `mpoly`/`mp`/`p` -> `poly`
- `medge` -> `edges`
- `med`/`ed`/`e` -> `edge`
`MLoop` variables aren't affected because they will be replaced
when they're split up into to arrays in #104424.
This offers overflow checking in debug builds, avoids implicit
conversion to pointers, slicing features for future convenience,
and clarifies ownership. Also switch naming to plural like most
other arrays for further clarification.
This pull request adds a new tipe of resource handles (thin handles).
These are intended for cases where a resource buffer with more than one
entry for each object is needed (for example, one entry per material
slot).
While it's already possible to have multiple regular handles for the
same object, they have a non-trivial overhead in terms of uploaded
data (matrix, bounds, object info) and computation (visibility
culling).
Thin handles store an indirection buffer pointing to their "parent"
regular handle, therefore multiple thin handles can share the same
per-object data and visibility culling computation.
Thin handles can only be used in their own Pass type (PassMainThin),
so passes that don't need them don't have to pay the overhead.
This pull request also includes the update of the Workbench Next
pre-pass to use PassMainThin, which is the main reason for the
implementation of this feature.
The main change from the previous PR is that the thin handles are now
stored directly in the main resource_id_buf, to avoid wasting an extra
bind slot.
Pull Request #105261
Previously [D16255](https://developer.blender.org/D16255)
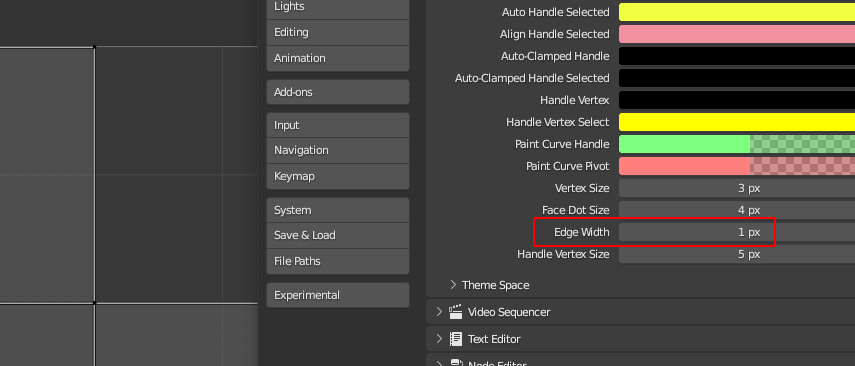
There is no option to adjust the edge_width like there is in the preferences for vertex_size and face_dot_size.
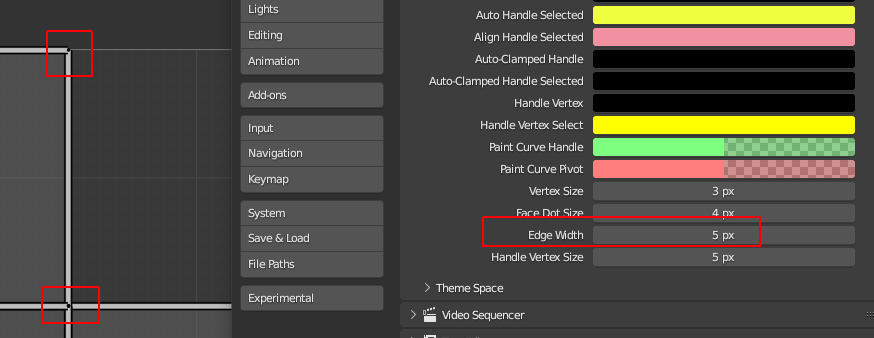
I only added the option for 3DView and UV/Image Editor, and limited both to a max size of 5 pixel, since the edges do not look very nice with too high values.
In the UV Editor only, there are always black outlines on the edges, I could not find a way to reduce the increasing thickness of these black outlines.
The default edge_width of 1 pixel:
Here the edge_width with a falue of 3:
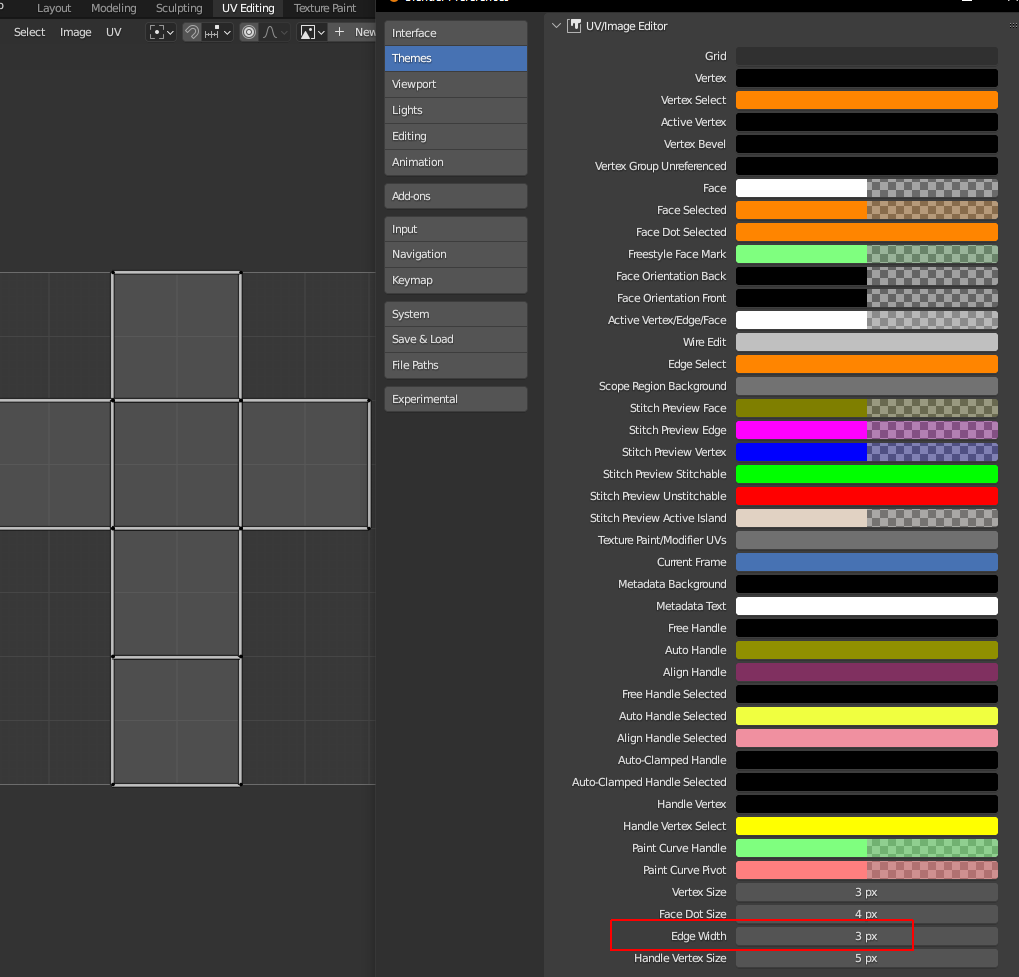
And here the visible increase of the dark border of the edges and their overlap (even at the maxed size of 5):
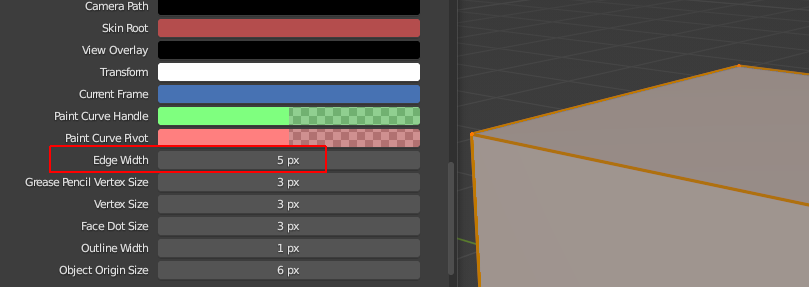
Lastly for the 3DView the max edge_width of 5 looks like this:
Pull Request #104741
For every other texture types this is expected to be implicitly
`GPU_DATA_FLOAT`. There is only one case where this is not the case.
I believe this was previously needed because the data type was
conditionning the texture creation. This is not the case anymore.
Using spans instead of raw pointers helps to differentiate ararys from
pointers to single elements, gives bounds checking in debug builds, and
conveniently stores the number of elements in the same variable.
Also make variable naming consistent. For example, use `loops` instead
of `mloop`. The plural helps to clarify that the variable is an array.
I didn't change positions because there is a type mismatch between
C and C++ code that is ugly to manage. All remaining code can be
converted to C++, then that change will be simpler.
Pull Request #105138
Complex EEVEE nodegraphs, particularly those combining
multiple principledBSDF shader nodes have a tendancy
to require a large number of simultaneous live registers
due to function call depth. In some instances, this
causes substantial performance drop and corruption if
the stack gets too large.
To mitigate this, splitting calls to closure_eval such
that only a single individual closure is evaluated in each
call reduces the number of live registers required. This
is preferred over using compound closure evaluation
functions which require a large amount of in-flight data.
Note that this is generally not more optimal, if the stack
does not spill, as there is an increased instruction count.
The specific trade-off depends on the exact architecture
in question. Hence, this is limited to AMD GPUs.
Authored by Apple: Michael Parkin-White
Ref #96261
Pull Request #104985
This reverts commit 19222627c6.
Something went wrong here, seems like this commit merged the main branch
into the release branch, which should never be done.
This reverts commit 68181c2560.
I merged 3.6 into 3.5 by mistake. Basically I had a PR against main,
then changed it in the last minute to be against 3.5 via the
web-interface unaware that I shouldn't do it without updating the
patch.
Original Pull Request: #104889
Note that the node group has its sockets names
translated, while the built-in nodes don't.
So we need to use data_ for the built-in nodes names,
and the sockets of the created node groups.
Pull Request #104889
Avoid running out of attributes when multiple material slots use the same one.
Cleanup:
Removes the return value from drw_attributes_add_request since it shouldn't be modified afterward and it's never used.
Avoid making copies of DRW_AttributeRequest in drw_attributes_has_request.
Co-authored-by: Miguel Pozo <pragma37@gmail.com>
Pull Request #104709
overlay_uniform_color_clipped was inheriting from overlay_depth_only, which doesn't
make much sense.
I've changed it to inherit from overlay_uniform_color instead, which is consistent
with other \*\_clipped variants of shaders.
Pull Request #104761
Certain material node graphs can be very expensive to run. This feature aims to produce secondary GPUPass shaders within a GPUMaterial which provide optimal runtime performance. Such optimizations include baking constant data into the shader source directly, allowing the compiler to propogate constants and perform aggressive optimization upfront.
As optimizations can result in reduction of shader editor and animation interactivity, optimized pass generation and compilation is deferred until all outstanding compilations have completed. Optimization is also delayed util a material has remained unmodified for a set period of time, to reduce excessive compilation. The original variant of the material shader is kept to maintain interactivity.
Also adding a new concept to gpu::Shader allowing assignment of a parent shader from which a shader can pull PSO descriptors and any required metadata for asynchronous shader cache warming. This enables fully asynchronous shader optimization, without runtime hitching, while also reducing runtime hitching for standard materials, by using PSO descriptors from default materials, ahead of rendering.
Further shader graph optimizations are likely also possible with this architecture. Certain scenes, such as Wanderer benefit significantly. Viewport performance for this scene is 2-3x faster on Apple-silicon based GPUs.
Authored by Apple: Michael Parkin-White
Ref T96261
Pull Request #104536
This adds a new overlay for curves sculpt mode that displays the curves that the
user currently edits. Those may be different from the evaluated/original curves
when procedural deformations or child curves are used.
The overlay can clash with the evaluated curves when they are exactly on top of
each other. There is not much we can do about that currently. The user will have
to decide whether the overlay should be shown or not on a case-by-case basis.
Pull Request #104467
This renames `data` and `color` to `selection`. This is better because
it's actually what the corresponding buffers contain. Using this
more correct name makes sharing vertex buffers between different
gpu batches for different shaders easier.