Add Fractal Voronoi Noise V.2 #106827
No reviewers
Labels
No Label
Interest
Alembic
Interest
Animation & Rigging
Interest
Asset System
Interest
Audio
Interest
Automated Testing
Interest
Blender Asset Bundle
Interest
BlendFile
Interest
Code Documentation
Interest
Collada
Interest
Compatibility
Interest
Compositing
Interest
Core
Interest
Cycles
Interest
Dependency Graph
Interest
Development Management
Interest
EEVEE
Interest
Freestyle
Interest
Geometry Nodes
Interest
Grease Pencil
Interest
ID Management
Interest
Images & Movies
Interest
Import Export
Interest
Line Art
Interest
Masking
Interest
Metal
Interest
Modeling
Interest
Modifiers
Interest
Motion Tracking
Interest
Nodes & Physics
Interest
OpenGL
Interest
Overlay
Interest
Overrides
Interest
Performance
Interest
Physics
Interest
Pipeline, Assets & IO
Interest
Platforms, Builds & Tests
Interest
Python API
Interest
Render & Cycles
Interest
Render Pipeline
Interest
Sculpt, Paint & Texture
Interest
Text Editor
Interest
Translations
Interest
Triaging
Interest
Undo
Interest
USD
Interest
User Interface
Interest
UV Editing
Interest
VFX & Video
Interest
Video Sequencer
Interest
Viewport & EEVEE
Interest
Virtual Reality
Interest
Vulkan
Interest
Wayland
Interest
Workbench
Interest: X11
Legacy
Asset Browser Project
Legacy
Blender 2.8 Project
Legacy
Milestone 1: Basic, Local Asset Browser
Legacy
OpenGL Error
Meta
Good First Issue
Meta
Papercut
Meta
Retrospective
Meta
Security
Module
Animation & Rigging
Module
Core
Module
Development Management
Module
Grease Pencil
Module
Modeling
Module
Nodes & Physics
Module
Pipeline, Assets & IO
Module
Platforms, Builds & Tests
Module
Python API
Module
Render & Cycles
Module
Sculpt, Paint & Texture
Module
Triaging
Module
User Interface
Module
VFX & Video
Module
Viewport & EEVEE
Platform
FreeBSD
Platform
Linux
Platform
macOS
Platform
Windows
Severity
High
Severity
Low
Severity
Normal
Severity
Unbreak Now!
Status
Archived
Status
Confirmed
Status
Duplicate
Status
Needs Info from Developers
Status
Needs Information from User
Status
Needs Triage
Status
Resolved
Type
Bug
Type
Design
Type
Known Issue
Type
Patch
Type
Report
Type
To Do
No Milestone
No project
No Assignees
10 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: blender/blender#106827
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "Hoshinova/blender:add-fractal-voronoi"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
A continuation of https://archive.blender.org/developer/D16262
Following the discussions there I decided to work more closely with artists which resulted in this thread on blenderartists.org.
Using their suggestions I updated my original implementation of Fractal Voronoi Noise to Fractal Voronoi Noise V.2.
Since there are some differences between the original implementation and V.2 I will write a new documentation here:
For the F1, Smooth F1, F2 Feature:
Distance and Color outputs:
Multiple Layers of Voronoi Noise are computed and outputs of each layer added together to create the final output.
The amount of layers is being controlled by the "Detail" input.
If the "Detail" input has a non-integer value two instances of Fractal Voronoi will be computed with each having the greatest whole integer smaller than the "Detail" input value and the smallest whole integer greater than the "Detail" input value as the amount of layers respectively.
The fractional part of "Detail" will then be used as a factor to do a linear interpolation between the two instances.
The Distance output of each layer is being multiplied by the "Roughness" input to the power of the current layer-1.
This means that for example if the "Roughness" input is 2.0 the the Distance output of the first layer is being multiplied by 2.0 ^ 0 = 1.0 for the second layer it being multiplied by 2.0 ^ 1 = 2.0 for the third layer it is being multiplied by 2.0 ^ 2 = 4.0 and so on.
The Scale input of each layer is being multiplied by the "Lacunarity" input to the power of the current layer-1.
Position output:
Essentially the same as with the Distance and Color outputs but instead of adding the layers together a linear interpolation is performed using the Roughness input as the lerp factor.
For the Distance to Edge Feature:
Multiple Layers of Voronoi Distance to Edge Textures are computed and the resulting Distance output is the minimum of the Distance output of all layers.
The amount of layers is being controlled by the "Detail" input.
If the "Detail" input has a non-integer value two instances of Fractal Voronoi will be computed with each having the greatest whole integer smaller than the "Detail" input value and the smallest whole integer greater than the "Detail" input value as the amount of layers respectively.
The fractional part of "Detail" will then be used as a factor to do a linear interpolation between the two instances.
The Roughness input is used to lerp between the current layer and the previous layer.
The Scale input of each layer is being multiplied by the "Lacunarity" input to the power of the current layer-1.
Additionally a Normalize boolean input is added which if checked will remap the Distance and Color outputs to a [0.0, 1.0] range.
Unlike for the other features
F2normalization doesn't actually calculate the maximal amplitude.This is mainly because the actual maximal amplitude of
F2is very expensive to compute.Thus it instead it uses the maximal amplitude of
F1scaled by a factor of 2.0, with the logic behind that being that the highestF2Distanceoutput is always\leqthe highestF1Distanceoutput times 2.0.As in the original diff thread there were requests for more practical use cases of Fractal Voronoi noise I will include some selected ones here:
Landscapes by Lumpengnom:



Fabric Patterns by KickAir_8P:

Hand Painted Wall by Hoshinova:

Unfortunately projects.blender.org won't let me upload more pictures but I can share some more variations in a comment if you want.
Apart from the already amazing still pictures shown above I want to specifically mention Tenkai Raiko's contribution to this.
Essentially he discovered that Fractal Voronoi noise can be used to procedurally simulate all kinds of smoke and fluid simulations using volumes.
Apart from being able to create procedural simulations of both arbitrary size and resolution with virtually no RAM overhead he has also shown that it gives the user a level of control not easily achievable using traditional simulaton methods.
All of this can be seen in the following video he posted to demonstrate said use cases:
https://www.youtube.com/watch?v=WCJm-g5ngSA
Please respect the creators wish and don't copy, repost or reupload any parts of the video.
Thank you for reading and reviewing my Pull Request!
Hi I'm Tenkai Raiko the creator of the Fractal Voronoi Noise Demonstration video.
As it seems, due to a combination of rendering at a low sampling count and YouTube's video compression most of the details in the render are gone.



To show that the volumes really have "infinite" resolution I'll upload a few screenshots here.
@blender-bot package
Package build started. Download here when ready.
My main concern with this is the amount of code it adds, almost 4000 lines for this feature is a lot, when it's not a critical feature in my opinion.
Isn't it possible to reduce that more? Some ideas:
VoronoiParamsstruct to pass arguments.VoronoiOutputstruct to return output.VoronoiOutput.I wouldn't want you to spend the time to do this for all implementations, but maybe just one and then @JacquesLucke and I can check if the complexity is acceptable?
Mark as request changes based on above comment.
I'll make the requested changes to the implementation in
voronoi.h.Just 2 questions before I do so:
What exactly do you mean by
"Add utility function to accumulate octaves into VoronoiOutput."?As for
"Maybe some of the differences between voronoi types can be switches deeper in the inner loop to avoid duplicate functions."I think that in the C++ implementations almost all duplicate functions can be avoided by using a combination of structs and templates, but that won't work in OSL and GLSL.
Is it OK if I do the changes just in
voronoi.hand see what can be done in OSL and GLSL?Looking at the OSL code for example, this part seems to duplicated in multiple functions. So that could be turned into a function.
Yes, let's first see what is possible in C++. For OSL/GLSL there will likely be a bit more duplication. Maybe a macro could be used if it really reduces code a lot.
But for example that code I pasted above is still duplicated 3x with the same type in OSL.
@brecht I was able to eliminate all duplicate functions in
voronoi.hby moving both theswitchstatements and the normalization functions into the fractalization functions.voronoi.hin my new optimized version of Fractal Voronoi V.2 has a total line count of exactly 1222 lines of code compared to the pre-optimized version which had 1574 lines.The version currently in the official main branch of Blender has a total line count of exactly 1152 lines, meaning that I was able to implement all features of Fractal Voronoi V.2 using just 70 additional lines of code.
The best thing about this is that methods I used to optimize
voronoi.hcan also be used to optimize the OSL and GLSL implementations.This means that 20 out of the 40 new fractalization functions can be eliminated leaving 20 in the optimized version and 56 out of the 64 new normalization functions can be eliminated leaving only 8 in the optimized version.
So if all optimizations are implemented there should be a code reduction of 50-60% meaning that the optimized version will likely add about 1500-2000 new lines of code in total.
Apart from that I also noticed a slight performance improvement in the optimized version of Fractal Voronoi V.2 of about 5%, nothing spectacular but pretty nice nonetheless.
What do you think?
@Hoshinova As I once told you, it would be much better to do a more general code cleanup first.
Now that you have been able to reduce copying, is it possible to say that you would make functions out of simple and understandable tasks? Or was this code unified only because of its large size and duplication?
Can we say that the ease of understanding of this code has not suffered, or even improved?
With additional features, it can be even harder to understand...
@mod_moder
"As I once told you, it would be much better to do a more general code cleanup first."I have already altered and cleaned up the code wherever it was necessary.
Apart from that the development of Fractal Voronoi noise already takes up all of the time I can devote to Blender Development.
It simply isn't feasible for me to do a general refactor of all the pre-existing code I touch.
"Now that you have been able to reduce copying, is it possible to say that you would make functions out of simple and understandable tasks? Or was this code unified only because of its large size and duplication? Can we say that the ease of understanding of this code has not suffered, or even improved?"The code is broken up so that each function logically does as few things as possible while also avoiding duplication. For example while there may not be a logical incentive to integrate the normalization step into the fractalization functions, doing so eliminates 56 duplicate normalization functions.
"With additional features, it can be even harder to understand..."Well yes, more features tend to lead to more complexity.
@Hoshinova I did a bit more refactoring, with those changes the amount of added complexity seems fine to me. It's probably also easier to port to OSL and GLSL with fewer templates.
https://projects.blender.org/brecht/paste/src/branch/main/svm_voronoi.patch
What do you think?
@brecht It generally looks pretty great to me, though I noticed that after your refactor all 4D outputs of F1, Smooth F1 and F2 have been somehow distorted when using the
Minkowskimetric:Reference:

After Refactor:

Difference:

Test .blend file:
Fractal_Voronoi_Test_File.blend
The strange thing is that it only appears when using the
Minkowskimetric in 4D meaning, that all other combinations of dimension and metric seem to be fine.But I also couldn't find anything that could be causing this bug, the only thing that is used specifically by the
Minkowskimetric is this line:Or maybe it's just a problem on my machine so could you please have a look at this?
Apart from that I have a question regarding the
const VArray<> &s inIs it better to keep using
VArrayreferences in aVoronoiParamsstruct, which would mean that they'd all need to be initialized using the constructor, or is it OK to just copy the return value of e.g.get_vector(param++)into a newVArray<>variable in theVoronoiParamsstruct?Which would look something like this:
params.vector = get_vector(param++);Also regarding the GLSL implementation, as far as I know the GLSL voronoi implementation starts in this file:
I don't see a general starting point for the GLSL version in that file where a
VoronoiParamsstruct could be initialized, so it would probably be best to do that in whatever function calls the GLSL Voronoi functions.But I have trouble finding that function as for example breaking points don't work in the GLSL files for some reason.
So could you please also tell me which function calls the GLSL Voronoi functions?
For the Minkowski distance, there was a bug in float4 pow that I fixed in main now:
63dfbdc.For
VArray, I guess it's best to keep the implementation innoise.ccscalar for now, includingVoronoiParams? To avoid making that much more complicated and keep it similar to the other implementations.If you structure the implementation similar to the SVM one, I think you can deduplicate may of the
get_vectorand similar calls as well.Those GLSL functions are chosen from
node_shader_tex_voronoi.cc. I guess there are two approaches there. Either there could be one function, relying on the optimizer to do good constant folding. Or all the functions could remain, with some macros to deduplicate code like packing the parameters into a struct.Umm what do you mean by keeping it scalar? Honestly I'm not sure what exactly
get_vectorand friends are doing in the first place, until now I've just been kinda copying how it's used everywhere else.Function nodes run on an array of values instead of individual ones, which helps improve performance. For example the feature/dimension switch only has to be done once for all elements.
The voronoi evaluation still runs on one element at a time, and I think it's fine to keep it like that. And so that would mean
VoronoiParamsdoes not need to contain aVArray. Rather you can construct it for every element, getting the values from theVArrayfor each input.@brecht I've made some final changes to
voronoi.h. I would then copy thevoronoi.himplementation to the other versions as closely as reasonable, so is there still anything you would like to have changed?The voronoi evaluation still runs on one element at a time, and I think it's fine to keep it like that. And so that would mean VoronoiParams does not need to contain a VArray. Rather you can construct it for every element, getting the values from the VArray for each input`
So do you mean something like this?:
But wouldn't getting the parameters every time be much slower than just copying the entire
VArrayintoVoronoiParamsonce?As for GLSL I'll just
#definea macro (something likeINITIALIZE_VORONOIPARAMS) which would take care of the initialization ofVoronoiParams.I meant something like this:
Are you sure about this? That looks like at least 200+ additional lines just to initialize
VoronoiParams, whats wrong with just copying theVArray?I'm not sure what you mean by just copying the
VArray, you need to go fromVArrayto single float values unless you wantnoise.ccto work withVArrayall the way through as well?If there is a lot of extra code, you could declare a
VoronoiVArrayParamsor something and have a utility function to get aVoronoiParamsfor one element out of that. Or put the switches inside the for loop at a small performance cost.Right, I completely forgot about
noise.cc, in that case I think I'll put the switch statement in the for loop, as it would probably still be faster than a function call and the performance difference isn't worth 200 lines of extra code.@mod_moder Well, looks like I did end up having to change a lot of the pre-exisitng code, so you did kind of get your general code cleanup after all ;-)
@Hoshinova And now you have 8500++ line changed PR, good luck and best health to reviewers, this main idea of splitting this in more PRs (:/
@mod_moder I'd figured you'll say that, but I honestly don't see how splitting this up into multiple pull requests would reduce the work for the reviewers in any way.
Apart from that as all the new code is rather interdependent, where would you wan't to split it up in the first place?
I didn't follow your progress very much, sorry.
@brecht I have a question regarding hash_float_to_float
Is the output range of the hash_x_to_y functions always in a [0, 1] interval or can it be different?
@blender-bot package
Package build started. Download here when ready.
@brecht It is done.
Or rather it works on my machine but according to https://builder.blender.org/admin/#/builders/136/builds/1158 there seem to be errors on other machines.
For https://builder.blender.org/admin/#/builders/135/builds/1135 it apparently can't find the new functions for some reason.
Meanwhile https://builder.blender.org/admin/#/builders/132/builds/1118 and https://builder.blender.org/admin/#/builders/132/builds/1118 don't seem to fail because of the code from Fractal Voronoi noise.
I'm not sure what exactly causes these errors (it works on my machine after all), could you please have look at it?
Apart from that I would say that after fixing those errors the code is finally ready to be merged into the
mainbranch.For the Metal errors you need to add the
ccl_privatequalifier for any pointer or reference argument. Also usemixinstead oflerp.The HIP errors seem to be some kind of compiler bug related to name mangling. Probably can be worked around somehow.
@blender-bot package
Package build started. Download here when ready.
@brecht
"For the Metal errors you need to add the ccl_private qualifier for any pointer or reference argument. Also use mix instead of lerp."Fixed that.
"The HIP errors seem to be some kind of compiler bug related to name mangling. Probably can be worked around somehow."And uhh, how do you do that?
Apart from that is there still something needed to be changed?
I've already tested all the different noise implementations to make sure that they all give out the same output.
I also didn't encounter any bugs during that process.
The performance difference for a single layer of Voironoi noise between the Fractal Voronoi Noise node and the Voronoi noise node currently in
mainbranch is less than 1%, as far as I can test.Well, looks like Metal is still complaining https://builder.blender.org/admin/#/builders/135/builds/1182
error: no matching function for call to 'reduce_add'Should I just change the
voronoi_distance()function invoronoi.hback to the old non templated version?I added
reduce_addforfloat2in main, that should make it work on Metal.Why not write the macros as as function-style? For instance:
I think this is cleaner and we can just eliminate
params.featureand any potential trouble that comes with it especially for GLSL.I am not sure why you are not using the single value constructors for vectors, but those can make the code more compact and cleaner, consider:
Vs:
Are the existing functions in
gpu_shader_material_voronoi.glslchanged in any way?@blender-bot package
Package build started. Download here when ready.
A huge problem I faced when writing the code for Fractal Voronoi noise was that there were a lot inconsistencies between the different implementation. This starts at small things like the same variables having different names, arbitrary extra variables and extra variables with the same name as a variable in a different implementation but having a different function, but it covers things like there being arbitrary extra cases, like
Minkowskiinvoronoi.cc.Not to mention the whole structure of the code was different in every implementation, for some implementations the noise layers were being evaluated inside the call function while in others it was done in a separate function, etc..
What all those inconsistencies meant was that I effectively had to write the same piece of code 4 times and since each implementation was slightly different it also had to be debugged separately. This actually significantly increases the amount of work to add anything, in fact I probably spent more time on porting the code across the 4 implementations than developing new features.
This is why when I did a general refactor of the complete code of Fractal Voronoi noise (including the pre-existing code) I tried to make different implementations match as closely as possible. Of course as the different programming languages have different features and constraints some changes had to be made, especially between the C++ and non-C++ versions.
If you look at the PR you will notice that the Cycles and Geo nodes versions are almost identical. Between those two versions and the OSL and GLSL versions there are some minor differences but the OSL and GLSL are in turn very close.
@OmarEmaraDev
Now getting to the specificly mentioned points:
In my latest commit I changed the macros to function macros, but kept
params.feature, for the reasons stated in my comment above. The C++ implementation uses templates instead of macros, which doesn't allow such kinds of substitutions in the function name. Apart from that I also plan to do some performance optimizations in for Voronoi after this PR for which I might needparams.featurein some other places.I didn't face any issues regarding
params.featurethough, what "potential trouble" do you have in mind?Done.
Yes all functions which evaluate some kind of Voronoi layer have been substituted using the versions from
voronoi.h, which however apart from the data types seem to be the same as the ones originally present.I am not the best person to give advice on how to do stuff in C++, but can't we just add the functions as template parameters and instantiate that function in an appropriately named function, or better yet, use an alias? I think compilers won't have any issue inlining that, so there won't be any performance concerns. For instance, see:
https://godbolt.org/z/GMM4GYcGo
I mean things like compilers failing to optimize those branches, which does happen especially for GLSL compilers. So I think it should not be kept for now. We can bring it back when it is really needed, as in the future optimizations you want to do.
Yes, we could but the thing is that it would add further complexity to those implementations for no apparent benefit.
The thing is for all versions other than GLSL, the decision of which feature is chosen needs to be at some point in the code, so if at all you'd have unoptimized branches either way.
GLSL is special in that point as that decision us done before entering the GLSL code, so this kind of branch optimization would only work in GLSL.
Of course we could also have a different implementation in GLSL, which i'd rather avoid though...
I am not convinced that this would complicate things much, but in any case, we can just wait for the opinion of other reviewers on the matter.
@OmarEmaraDev If it's just about performance I think your concerns are unfounded.
I did some performance tests and as expected, the performance difference for a single layer of Voronoi noise between the current Fractal Voronoi Noise node implementation and the Voronoi noise node currently in the main branch is less than 1% in EEVEE on an RTX 3070:
You can convince yourself using the packaged build from the buildbot and this test file:
Voronoi_Test_File_EEVEE.blend
That's fine, I am not trying to convince you that a performance regression is definite. But my concern was about different compiler implementations. Just because it is fine in a single compiler and platform does not mean that it will be fine for all other compilers.
Fair point. Let's see what Brecht's and Jacques's opinion are on that matter.
Ah and I also didn't experience a performance regression in Cycles on my machine.
Apart from that is there anything else needed to be changed?
I would expect
paramsto be effectively treated as a bunch of individual variables, andparams.featureto be easily constant folded. My guess would be it's fine to leave it unchanged. But I don't have a lot of experience with quirks of the latest GLSL compilers.@fclem I remember you saying that some GLSL compilers sometimes refuse to corporate and will not remove the branches even if the condition variable is a constant. Is it worth it to remove such branches, or can we just leave it as is?
For context, this is the code in question.
params.featureis a constant set by the caller:If it actually turns out that the branches fail to get optimized, I'd say it's bets to just a separate different implementation for GLSL then.
Instead of having the Fractalization process have it's own function I'd just write the macro so that's inlined directly in the calling function.
I'd then leave the other implementations unchanged because removing the branches will double the compile time for that part of code
But let's first see what @fclem has to say about this.
#98190 was the original bug that made me worried that this kind of optimization scheme was not viable. Even with
constkeyword are not enough for these compilers. But maybe that was because of the float comparison.If there is a problem with it, maybe just pass the technique parameter as part of the macro parameter and change the function name using macro name glue
voronoi_##technique()instead of havingifstatements. An example of this is in/source/blender/draw/engines/eevee/shaders/closure_eval_lib.glsl.@fclem I didn't experience any problems with it and I also already know a solution to this.
The thing is if we optimize out the if statements we'd get a GLSL implementation which is different from the other 3 implementations, which I want to avoid.
So the question to you is actually if there may be a problem, as I didn't experience any.
@Hoshinova I would say it is ok to commit in this state. We can change it if the issue arise. Also we are going to raise the minimum requirement for 4.0 so it might just work. 🤞
I have a few comments on code style, but overall it's much better than before! Besides those, the geometry nodes related code seems to be ready.
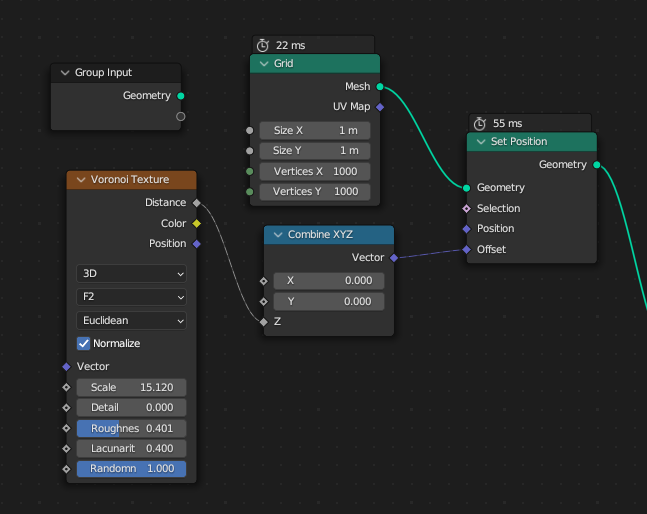
It would be nice if you could do a few simple performance comparisons in geometry nodes just to see that there are no significant performance regressions. Taking the measurements from the UI is good enough for this:
The results of the benchmark should be added to the patch description.
@ -250,3 +250,3 @@/* Linear Interpolation. */BLI_INLINE float mix(float v0, float v1, float x)template<typename T> T mix(T v0, T v1, float x)Add
static.@ -1375,1 +1383,4 @@float voronoi_distance_1d(const float a, const float b, const VoronoiParams ¶ms){/* Supress compiler warnings, not used for 1D. */(void)params;Use
UNUSED_VARS. Arguably,paramsshouldn't be passed in here in this case, but it's fine for now. Maybe it will be removed as part of a more general optimization pass on the code in the future./* params */?That's even better.
@ -1406,2 +1482,2 @@*r_w = targetPosition + cellPosition;}VoronoiOutput octave;octave->outputSame below.
Why output instead of octave? It only computes one octave not the entire output.
In my current understanding, the term "octave" only makes sense in the context of fractal noise. So using the term there is reasonable. But this function just computes noise directly, it doesn't care about multiple octaves.
Don't mind too much either way, I just found it a bit confusing when reading the code at first.
I see where you're coming from. Generally it's just a matter of point of view. You could see a single layer of Voronoi noise as it's own thing and Fractal Voronoi noise as multiple of them overlayed together, in which case it would make sense to use
output. Or alternatively you could see a single layer of Voronoi noise as a part of Fractal Voronoi noise in which caseoctavewould make more sense.Since the Voronoi functions currently aren't used outside of Fractal Voronoi noise I think keeping it at
octaveis the better option now.If there should be any issues regarding the naming we can always change it in the future, so I'll mark it as resolved for now.
@ -2340,0 +2236,4 @@float scale = 1.0f;VoronoiOutput output;bool zero_input = params.detail == 0.0f || params.roughness == 0.0f || params.lacunarity == 0.0f;const@ -2340,0 +2247,4 @@if (zero_input) {max_amplitude = 1.0f;output.distance = octave.distance;output = octave;@ -239,3 +304,3 @@}void call(const IndexMask &mask, mf::Params params, mf::Context /*context*/) const overridevoid call(const IndexMask &mask, mf::Params mf_params, mf::Context /*context*/) const overridemf_params->paramsSame below.
That would create a naming collision with
noise::VoronoiParams params;in line 376. And out of the option of renamingnoise::VoronoiParamsormf::ParamsI think that renamingmf::Paramsis the better option asnoise::VoronoiParamsis not only used much more often in the Voronoi code but should also be namedparamsto keep it consistent with the other implementations.Ah, didn't notice that. Seems ok then.
@ -274,1 +349,4 @@int param = 0;const VArray<float3> &vector = (dimensions_ != 1) ? get_vector(param++) : VArray<float3>{};const VArray<float> &w = (dimensions_ == 1) || (dimensions_ == 4) ? get_w(param++) :Use
ELEMmacro, same below.@OmarEmaraDev Given what Clement just said:
Is the GLSL implementation good now?
@JacquesLucke I changed most of the things you mentioned. Could you please have another look at the remaining two comments?
Regarding
I have to admit that I don't work with geometry nodes all that often. How do you imagine the performance comparisons to look like?
Take the .blend file linked below and fill in a table like the following:
Just come up with a few different tests (maybe 5 that measure different things). It does not have to be an exhaustive list, the purpose is just to get a feeling for the performance impact of this patch. A few percent slowdown are acceptable. We can probably optimize the code for a few common cases later.
This looks good from my side now. I could not find a significant performance impact with CPU and NVIDIA GPU rendering.
@JacquesLucke
3 strange cases with a twofold deterioration.
@JacquesLucke For all combinations of
featureanddimensionthere is neither a significant performance increase nor decrease except forSmooth F1.The reason why
Smooth F1is slower is probably due to the fact that some optimizations invoronoi_smooth_f1innoise.ccwere removed when I refactored the code. Previously only the output that was connected was being computed, while in the refactored version it always computes all outputs. This means that the performance is once again the same when multiple outputs are used, but is worse when only one output is used.The optimizations used in
voronoi_smooth_f1are only possible in geometry nodes though. So the question is whether it's acceptable to keep the code consistent with the other implementations for this PR and to optimize it later on.Or if it's bad enough to need to be optimized right away, which however would also mean that parts of the implementations of
F1andF2may need to be changed as well as they partly depend on the same pieces of code.We could also try an intermediate way of both.
My theory is that for
Smooth F1it's theColoroutput that drives up the computing time.I could just optimize the
Coloroutput instead of all 3 outputs as is the case inmain.This alone may be enough the reach performance parity again, while keeping the difference to the other implementations minimal.
So I think that option would be the best... If it works.
Would be good if you could try the optimization you just mentioned. Mainly to see if it works and how much complexity it adds. If it's too much complexity, we can also do it separately later. I think the optimization is important enough to justify different code.
@Hoshinova, here is a workaround for the HIP compiler bug:
@JacquesLucke Looks like my intuition was correct:
Optimizing
Coloralone is enough to reach performance parity.@blender-bot package
Package build started. Download here when ready.
There is one thing worth to mention about
Normalize.For
F1,Smooth F1andDistance to Edgeit is mathematically guaranteed that theDistanceoutput is in a [0.0, 1.0] range.That is not the case for
F2.The reason for that is that unlike for the other features
F2normalization doesn't calculate the maximal amplitude.This has 2 reasons: Firstly, the actual maximal amplitude of
F2is very expensive to compute. Secondly, the actual maximal amplitude ofF2is usually significantly greater than the mean value, meaning that dividing by it would excessively reduce theDistanceoutput in most cases.Instead it uses the maximal amplitude of
F1scaled by a factor of 2.0, with the logic behind that being that theF2Distanceoutput is usually less than 2.0 times greater thanF1.In theory this could result to the output being greater than 1.0 with very particular arrangements of feature points, however as the distribution of feature points is randomized this doesn't actually happen in practice (as far as I have tested it).
So if in the future there are bug reports about the normalized
F2Distanceoutputting values greater than 1.0 for certain input combinations, it's a known limitation.@brecht @JacquesLucke @OmarEmaraDev
Looks like everything is done.
Are we ready to merge?
@ -2167,2 +2081,2 @@correctionFactor;}correctionFactor /= 1.0f + 3.0f * params.smoothness;if (calc_color) { /* Only compute Color if necessary, as it is very expensive */Comment style: move comment to its own line below and end with a
..WIP: Add Fractal Voronoi Noise V.2to Add Fractal Voronoi Noise V.2We will need release notes and user manual docs for this. @Hoshinova, could you help with this?
The release notes can have a relatively short explanation of what the changes are, with maybe 2 images showing it in action. And then the user manual can have a more detailed explanation.
Voronoi Texture Node
144ad4d20bBelow is a demonstration with left plane only showing the Voronoi output and the right plane showing the node tree using that output as a bump map in EEVEE.
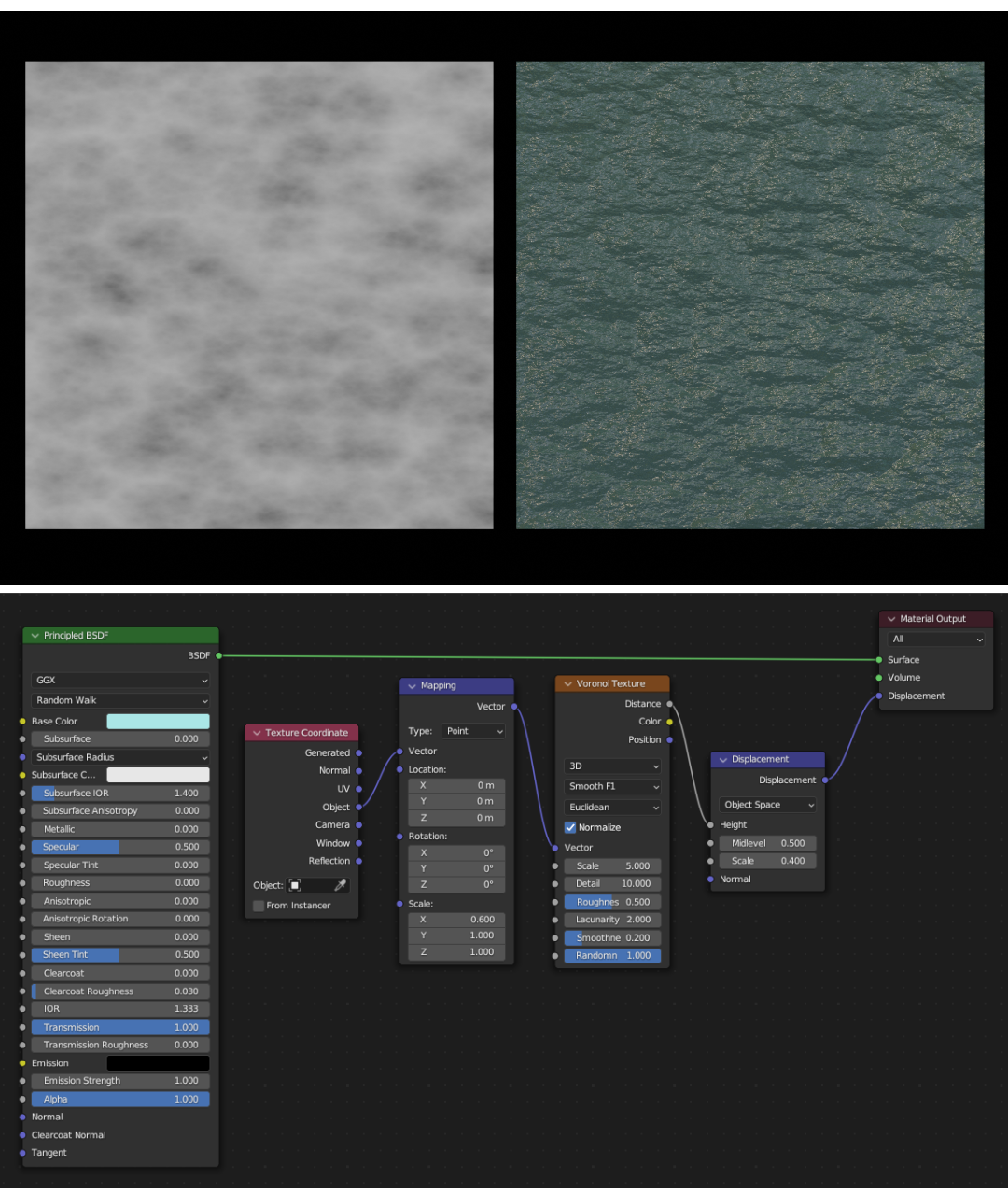
@brecht That is for the release notes.
I'm quite busy right now, so I can't make the user manual entry immediately. I might be able to next week, but it could also take a little longer than that.
Since the 4.0 release is still far away I take that it's not that urgent?
Thanks, I've put the text in the release notes now. For the images, I don't normally put UI screenshots in there, and the green bump map is a bit too much programmer art. Also I prefer the images to be separated instead of composited into one bigger images.
Maybe just some 2D images with example patterns would be better. Like the left pattern in your image, the hand painted wall, the fabric patterns in 2D instead of applied to a 3D model. Or 3 images showing progressively more octaves to explain a bit what this does.
@brecht
What about this:
I think it describes the concept of Fractal Voronoi noise pretty well.
I'd put it in both the release notes and the user manual.
I think that's a bit technical, mainly users want to see what the new parameters do, not so much how the implementation works. We also should avoid text in images like this, because it can't be translated, updates are difficult, doesn't work with screen readers, and doesn't follow the fonts and style of the website automatically.
I would rather have some images over the parameter range, some examples:
https://docs.blender.org/manual/en/latest/render/shader_nodes/textures/voronoi.html
https://wiki.blender.org/wiki/Reference/Release_Notes/2.83/Cycles
https://docs.blender.org/manual/en/latest/render/shader_nodes/shader/hair_principled.html
Do you mean something like this?:
Detail = 1.0:

Detail = 2.0:

Detail = 4.0:

Roughness = 0.25:

Roughness = 0.5:

Roughness = 1.0:

Lacunarity = 2.0:

Lacunarity = 4.0:

Lacunarity = 8.0:
@brecht I've got a small correction to make.
For the release notes I wrote
This is actually incorrect. Due to certain monotony properties of the functions involved it can be shown that F2 max_amplitude
\leq2 * F1 max_amplitude.Therefore the F2 Distance output may not exceed 1.0 when "Normalize" is checked.
Could you please remove those 2 sentences from the release notes? Thanks!
Thanks, I updated the release notes text and images:
https://wiki.blender.org/wiki/Reference/Release_Notes/4.0/Cycles#Fractal_Voronoi_Texture