Geometry Nodes: allow naming geometry sets #114910
No reviewers
Labels
No Label
Interest
Alembic
Interest
Animation & Rigging
Interest
Asset System
Interest
Audio
Interest
Automated Testing
Interest
Blender Asset Bundle
Interest
BlendFile
Interest
Code Documentation
Interest
Collada
Interest
Compatibility
Interest
Compositing
Interest
Core
Interest
Cycles
Interest
Dependency Graph
Interest
Development Management
Interest
EEVEE
Interest
Freestyle
Interest
Geometry Nodes
Interest
Grease Pencil
Interest
ID Management
Interest
Images & Movies
Interest
Import Export
Interest
Line Art
Interest
Masking
Interest
Metal
Interest
Modeling
Interest
Modifiers
Interest
Motion Tracking
Interest
Nodes & Physics
Interest
OpenGL
Interest
Overlay
Interest
Overrides
Interest
Performance
Interest
Physics
Interest
Pipeline, Assets & IO
Interest
Platforms, Builds & Tests
Interest
Python API
Interest
Render & Cycles
Interest
Render Pipeline
Interest
Sculpt, Paint & Texture
Interest
Text Editor
Interest
Translations
Interest
Triaging
Interest
Undo
Interest
USD
Interest
User Interface
Interest
UV Editing
Interest
VFX & Video
Interest
Video Sequencer
Interest
Viewport & EEVEE
Interest
Virtual Reality
Interest
Vulkan
Interest
Wayland
Interest
Workbench
Interest: X11
Legacy
Asset Browser Project
Legacy
Blender 2.8 Project
Legacy
Milestone 1: Basic, Local Asset Browser
Legacy
OpenGL Error
Meta
Good First Issue
Meta
Papercut
Meta
Retrospective
Meta
Security
Module
Animation & Rigging
Module
Core
Module
Development Management
Module
Grease Pencil
Module
Modeling
Module
Nodes & Physics
Module
Pipeline, Assets & IO
Module
Platforms, Builds & Tests
Module
Python API
Module
Render & Cycles
Module
Sculpt, Paint & Texture
Module
Triaging
Module
User Interface
Module
VFX & Video
Module
Viewport & EEVEE
Platform
FreeBSD
Platform
Linux
Platform
macOS
Platform
Windows
Severity
High
Severity
Low
Severity
Normal
Severity
Unbreak Now!
Status
Archived
Status
Confirmed
Status
Duplicate
Status
Needs Info from Developers
Status
Needs Information from User
Status
Needs Triage
Status
Resolved
Type
Bug
Type
Design
Type
Known Issue
Type
Patch
Type
Report
Type
To Do
No Milestone
No project
No Assignees
6 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: blender/blender#114910
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "JacquesLucke/blender:geometry-names"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
This adds a new
namemember to theGeometrySetclass. This name can be set with the newSet Geometry Namenode. Currently, the name is only used in the spreadsheet when displaying instances.The main purpose of this name is to help debugging in instance trees. However, in the future it may also be used when exporting instance trees or when creating separate objects from them.
Note, the name is not expected to be unique, it is fully in user control.
Naming geometries is necessary to make the spreadsheet more useful for instances, because currently the user has no information for which geometry is used by each instance.
We also want to use this name to improve the integration with grease pencil where sometimes layers become instances with the same name.
Code-wise this looks good.
@ -137,2 +137,4 @@public:/*** This is a user defined name for this geometry. It is not expected to be unique. It's mainThis is a->AIt's main->Its mainIt did feel a bit weird to me initially to add a feature like this that is mainly for debugging in a way that it actually affects and integrates into your node-tree while the data cannot actually be retrieved and used in the node-tree itself. But after testing it for a bit, I do think it's fine.
Would be good to have some nodes around extracting this information into string attributes once those are a thing to make it more useful.
Some notes:
Object/Collection Infonodes would also write the geometry name to the output. (I could have sworn this was already a thing somehow...)Both of these things are not very controversial I think, but would already leverage the simple initial version of this to a more useful capacity. Not sure how this looks on the implementation side though. Let me know if you think these things aren't realistic or should be a separate PR.
Name Propagation
I do have some thoughts regarding propagating this information in the node-tree. The way it works right now feels to me like it hasn't been specifically designed, but is rather a consequence of the way things are implemented, so I think we need to put a bit more thought into this.
At first I thought about handling the case for joining geometry. From the user perspective it's not immediately obvious to me why joining would lose the name, even if for example there is just one input, or all names of the inputs are the same.
I can generally understand why some operations might construct an entirely new geometry set and would thus clear the name, but to some degree this seems like more of an implementation detail. For the join node, I think, it is arguable since we have an explicit order of inputs, that is relevant for the way things are joined, already regarding index order, that the first input can be considered a main input that things are joined into. The same is the case also for the
Separate Componentsnode. So it wouldn't be unreasonable to me to propagate the name of the first geometry. Again it feels more like the reason for the fact that it does not propagate the name is more so the implementation of the node than a design decision. TheSeparate Geometrynode for example does propagate the name to both ouputs.In a broader scope when looking at entire node-trees, most operations right now do actually just propagate the name.
For nodes like
Set Positionthat just operate on attribute data it is quite obvious why you would keep the name the same. But at the same time, when viewing both the geometry before and after the operation in the spreadsheet they would not be one geometry set, but still share the same name.But even the 'conversion' nodes that reconstruct the data in a different geometry component like curve to mesh, points to volume, instance on points propagate the name at the moment. This can potentially result in a lot of confusing duplication of names for different geometry sets, since essentially any geometry that results from a named geometry set will inherit that name.
And since there is a difference in this propagation between nodes, I do feel like there is an additional source for confusion coming from the fact that some operations propagate the name while others don't. I think it's a lot more clear if we put the responsibility of clearing the name entirely on the user, rather than doing it in certain cases.
So the most hardcore approach would be to immediately clear the name with every geometry node, which I don't think is a good idea.
Another approach would be to differentiate the behavior based on specific nodes based on some rule. The way it's done right now though, shows me that this can seem quite arbitrary, since it immediately makes assumptions over the way that the user attaches semantic meaning to that operation, which we should generally avoid. (e.g. after attaching some buttons to a shirt, I might still want to call it a shirt)
My Conclusion
Personally I would propose to keep things broadly as they are, but indeed extend the name propagation to all nodes that have a geometry in and output that have a reaonable association, so including Join and Separate. (I'm not sure how many more examples there are that I'm missing)
Overall I think it is worth considering a way to identify unique geometry sets in the spreadsheet beyond the name to alleviate the resulting confusion. E.g. showing a hash in gray text next to the name that is actually unique. Potentially also identifying unmodified collection/object data would be useful.
I understand that this goes beyond the scope of this PR, but imo it's a crucial aspect to how we approach the propagation of this data to make sure unique geometries are still differentiable.
I agree with the @SimonThommes ' issues and this is why i would be against this kind of meta data. On good terms, there should be no meta data at all.
Any changes to implementation and functionality of node will cause problems here.
My approach would be something like: meta data on links between sockets. If it is a
Rerouteor a group node, then the metadata passes through. In any other case, the metadata is lost. If the node group implementation can get the metadata intarnally (with matched name and type), then everything is working correctly. Otherwise the error message...But i see that it seems that this is not what the goal of this PR is...
That's a great concept.
Even without a complete sting attribute implementation, I can already think of several use cases that would benefit from it.
I tested it for a bit, and aside from what Simon has said, I want to raise another UX point.
I understand the implementation reason that the 'set geometry name' is defined on the geometry level, nonetheless, as I see it, the geometry name is only relevant within the context of multiple geometries or the instance domain.
IMO, even though the data itself is part of the geometry set, controlling it from the instance domain may be more intuitive.
For example, after importing a cube object as an instance, you may want to rename the geometry default name (which is working fine in my tests). In the current proposal, the way to achieve that would be to realize the object, set its name, and then convert it back into an instance.
And from another aspect, if someday you would add the option to access it, it would probably be from the instance domain and not from the geometry itself.
A problem is that the name is not really on the instance domain, because that would mean that different instances could have different names even if they reference the same geometry. I know you probably mean to store the name only in the
InstanceReference. Technically, that can work, but it doesn't seem more convenient to me right now.I don't quite understand the need to realize the object.
Actually, I don't really mind where it is stored, it can be kept on the geometry, but it should be accessed and changed from the instance domain. It's the same way that the 'Fill Curve' node can work on the instance domain, but it actually changes data at the geometry level.
It is like how two geometries can have the same name - in contrast to mesh data.
My main point is not 'where should the name be stored' but 'where should the user interact with the geometry name' in an escense I am being deliberately ignorant of the technical side of this.
My ultimate question is: what is the purpose of the node? In what scenario and how would it be used?
As I see it, the purpose of the node is to distinguish and associate geometries in the context of other geometries, aka within the Instance domain.
As for the 'scenarios it may be used in', currently, the design is only about visualization and debugging, but still, even the debugging is only relvant within the context of the instance domain.
I can imagine many utility nodes that can read (selecting) and write (swapping instance reference) that could utilize the 'geometry name', of course, all of them would also be from the POV of instances.
I often find myself tossing around multiple instances stored on an object (with a geometry node). In my example above, the key part is that you import the object as an instance -> you'll have to realize it for changing its name.
@blender-bot build
What is the reason that you removed the text field from the input? I think it should be there.

Hm, good point, not sure why it's done, will check.
This issue is in main...
This was fixed in
main.@ -150,0 +152,4 @@* purpose is help debugging instance trees. It may eventually also be used when exporting* instance trees or when creating separate objects from them.*/std::string name;This string can not be shared and will be cause of large memory usage in common case with a lot of levels of nesting instances. In one level, here is just one instance handler so there is no a lot of geometry copy. But in case there is 2 levels, there is N copies of geometry. And since this string is not limited for its length here is can be really long text.
It does use some extra memory, but I don't quite get the case that you describe. The
GeometrySetis not stored for each instance separately, so it's not copied as often as you make it sound. I don't think this is something we need to be concerned about right now. There are ways to optimize it if we really need to in the future, but those also increase complexity.The case that i describe is:
GeometrySet -> InstanceComponent -> InstanceHandle -> GeometrySet -> InstanceComponent -> InstanceHandle -> GeometrySet.
In this chain, 1 first geometry set, 1 second geometry set that is instantiated. So, last one is also just one.
But let there will be 2 different geometry at second level, with the same instances at 3 level. Now here is 2 copy of the most nested geometry.
Yeah, not a cause of concern for me currently.
Jacques Lucke referenced this pull request2024-07-06 16:43:08 +02:00
Glad you addressed these already! That feels pretty good now imo.
I think it would be good to expose also the top level geometry set name somewhere. This could be shown in the tooltip of the geometry socket for example. I'm not sure where it would fit in the spreadsheet. Maybe in the breadcrumbs (?)
But generally I think this is pretty much good to go
I did this now. If there is a non-empty name, it will show in the tooltip.
It will show there for instances (once #124186 is ready). We could show it there too (maybe only when using a viewer?), but that can also be done separately.
Looks great!
I was thinking about that as well, I think that could be fine, since then it would actually have value to inspect. I'd say let's try that. It feels weird to me to not show it in the spreadsheet, so I'd do it as part of this PR tbh
It's unfortunately not trivial right now because the breadcrumbs are currently drawn in Python and there is no access to the geometry set currently. We should probably move the code from
space_spreadsheet.pyto C++, but that's a bit more involved. If you insist, I can do this refactor first as a separate patch, but I'd rather do it separately afterwards to have fewer interdependent patches.Ah okay, sure. It's fine to do separately then. I'll give this PR a final look now
The tooltip is very helpful imo!
It does reveal something that I'm not sure about:

The other way around when instancing layers are removed I definitely think it makes sense to keep the top level name.
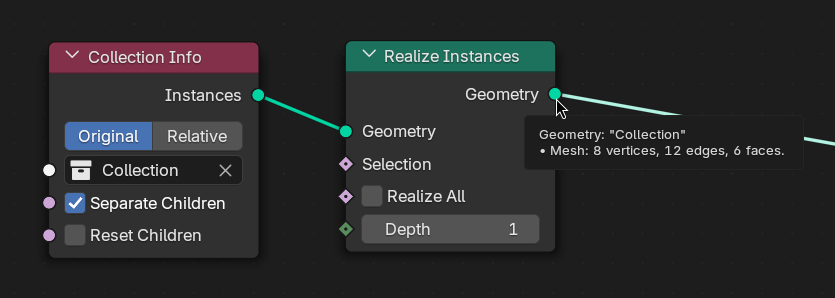
Also in this case, I think it's fine, since there is one explicit geometry that the instances are created on

So I think the
Geometry to Instancenode (which I could swear we wanted to rename toGeometry to Instancesages ago) is more of an exception where a new container geometry nodes set is created that should not have a name. Effectively, right now we end up with 2 different levels of instancing that have the same name. That's unique to this node, I believe and is probably confusing.The way the

Split to Instancesnode handles this seems fine to me, where only one level ends up with the nameI do feel more and more that these decisions are a little bit arbitrary though...
Also, this here seems straight up wrong, no? Maybe an implicit sharing issue?

I changed it so that the Geometry to Instance node only propagates the name when there is exactly one input. This feels reasonable to me.
Good find, fixed.
I thought about that option as well, but I do find it odd that then we still end up with the situation that the propagation ends up with the same name on multiple instancing levels. To be honest, I'd either revert to falling back to the first one or not propagate at all, I think. Changing the behavior this much depending on the number of inputs seems more confusing than helpful imo.
Regarding
bc24c5294adon't propagate name in Geometry to Instance nodeJust want to add that I think this behavior is consistent with the fact that we don't propagate (attribute) data from the instanced geometry up to the instance domain (except for specific cases, like the
Split to Instancesnode). This is just a more specialized aspect of that.This is good to be merged to me now. I'm not entirely certain we're not missing any corner cases, where the propagation behavior could be tweaked, but that can still be ironed out, if we run into something.