Apparently, the 65bit Intel architecture is presented differently
on Linux and Windows.
Allow both variants for the command line, so that semantically the
command line argument can be seen as a lower case platform.machine.
When updating a mesh, the GPU Subdivision code makes calls to
`GPU_indexbuf_bind_as_ssbo()`.
This may cause the current VAO index buffer to change due to calls from
`glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, ibo_id_)` in
`GPU_indexbuf_bind_as_ssbo()`.
The solution is to unbind the VAO (by calling `glBindVertexArray(0)`)
before creating the index buffer IBO.
Co-authored-by: Germano Cavalcante <grmncv@gmail.com>
Pull Request #104873
Possible values are x86_64 and arm64.
Allows to use make_update.py in a cross-compile environment, like
building x86_64 macOS Blender from Apple Silicon machine.
Pull Request #104863
In the Dope Sheet and the Timeline, it was possible to drag the view until the keyframes were completely out of view.
(Important to drag in the region with the keyframes, dragging in the channel box already did clamping)
This patch adds a clamping mechanism matching that of the channel box. That means the last channel will stick to the bottom of the view.
Co-authored-by: Christoph Lendenfeld <chris.lenden@gmail.com>
Pull Request #104516
Fix a crash when using the Euler Filter from the Graph Editor on baked curves.
The crash happened because baked curves have no bezt array.
Skipping any curves where that was missing fixes the issue.
Co-authored-by: Christoph Lendenfeld <chris.lenden@gmail.com>
Pull Request #104858
3.2 and 1.6 where used as rough equivalents to M_PI & M_PI_2, however
this raised questions about the significance of these values.
Running thousands of tests with generated euler inputs I wasn't able to
detect a difference so use M_PI & M_PI_2 instead.
Fix a crash when using the Euler Filter from the Graph Editor on baked curves.
The crash happened because baked curves have no bezt array.
Skipping any curves where that was missing fixes the issue.
Co-authored-by: Christoph Lendenfeld <chris.lenden@gmail.com>
Pull Request #104858
According to the report it is a regression since 3.2, but it is tricky
to pin-point which exact commit caused it.
The root of the issue is that under certain circumstances frame might
be read and processed twice, depending on the order in which panels and
the main area is drawn: the footage information panel skips cache, so
it it is drawn prior to the main area it leads to 2 frame reads. Opening
the Metadata panel triggers code path which forces frame to be put to
the cache, solving the double frame read.
Solution is simple: do not skip cache when acquiring image buffer for
the footage information: the same frame will be needed for the main
area as well.
Pull Request #104860
On a user level there are no expected changes, other than being able
to update submodules and libraries from a main repository at a detached
HEAD situation (which did not work before).
On the infrastructure level of things this moves us closer to ability
to use the main make_update.py for the buildbot update-code stage, and
to remove the update-code section from the pipeline_config.yaml.
The initial idea of switching make_update to the pipeline config did
not really work, causing duplicated work done on blender side and the
buildbot side. Additionally, it is not easy to switch make_update.py
to use pipeline_config.yaml because the YAML parser is not included
into default package of Python.
There will be few more steps of updates to this script before we can
actually clean-up the pipeline_config: the changes needs to be also
applied on the buildbot side to switch it to the actual make_update.
Switching buildbot to the official make_update.py allows to much more
easily apply the submodules change as per #104573.
Having a threshold well above PI would result in discontinuity in some
cases.
The discontinuity can be measured by generating euler values (both
random and interpolated rotations), then comparing the accumulated
difference.
Changing the threshold for wrapping rotations produces at least as good
or more compatible results.
This was reported as #17297 and fixed in [0], however the change was
only applied for the game-engine.
Ref !104856
[0]: ab44742cf3
This was broken even before 0649e63716 and was always expanding the
`Image`, not the movie clip (even if the source was set to
`CAM_BGIMG_SOURCE_MOVIE`)
Now the rule here seems to be to always expand unconditionally, so
remove checking the source and always expand image and movie clip.
Co-authored-by: Philipp Oeser <philipp@blender.org>
Pull Request #104815
* Repeat last operator now works for mesh filters.
* Added an iteration_count property to repeat the filter.
This is especially useful when compounded with the repeat
last operator tool.
* The mouse event history is stored for mesh filters
with more advanced user input (mostly Smooth and Relax
filters).
meson defaults to debug builds [0] unless you tell it differently, this
diff changes the options for
- epoxy
- fribidi
- harfbuzz
- wayland
- wayland_protocols
to be optimized, mesa was already optimized
[0] https://mesonbuild.com/Builtin-options.html#core-options
Pull Request #104802
Passing a `BitSpan` is generally better because then the caller is not
forced to allocate the bits with a `BitVector`. Also, the `BitSpan` can
be stored in the stack, which removes one pointer indirection compared
to accessing bits through a `BitVector &`.
This adds `BitSpan` and `MutableBitSpan`. They work essentially the same as
the normal `Span` and `MutableSpan`, but work on individual bits instead
(the smallest type `Span` can handle is one byte large).
This also splits up `BLI_bit_vector.hh` and introduces two new headers:
`BLI_bit_ref.hh` and `BLI_bit_span.hh`.
The goal here is to make working with dynamically sized bit masks more
convenient. I'm mainly working on this because I might want to use this
in #104629. It can also be used to cleanup function signatures that
currently take a reference to a `BitVector`. Like with `Span` vs. `Vector`,
it is better to pass a `BitSpan` to function than a `const BitVector &`.
Unit tests for the new code are included.
Pull Request #104671
Cycles uses the "split faces" mesh function to support sharp edges
and auto-smooth. However, 75ad8da1ea updated that
function to ignore the edges that are explicitly tagged as sharp and
only use the edge angle. Fix by taking the attribute into account too.
The custom data layer mappings from dfacaf4f40 were created
*before* the BMesh shape key layers were added, invalidating the BMesh
data offsets they stored. Fix by creating the mappings after all layers
have been created.
Clean up logic to make it more clear and formalize the way to choose
fixed node data type based on operation. This make possible to more
easily fix wrong node data type for color type and less than ops.
Pull Request #104617
Fix: The BKE_nlatrack_remove_and_free (#104752) unit test leaks a little memory. Cleaning up the rest of the track list to ensure everything is freed.
Co-authored-by: Nate Rupsis <nrupsis@gmail.com>
Pull Request #104839
This PR adds 2 new methods:
* BKE_nlatrack_remove
* BKE_nlatrack_remove_and_free
and modifies the existing `BKE_nlatrack_free` to remove the track list parameter.
This refactor splits out the removal / freeing into it's own methods, and provides a higher order method (BKE_nlatrack_remove_and_free) to conveniently call both.
Co-authored-by: Nate Rupsis <nrupsis@gmail.com>
Pull Request #104752
When appending assets it often isn't expected for the asset tags and
meta-data to be included. Add an option to the append operator to
disable appending the asset data, exposing existing internal options.
This adds the "Select More/Less" operators for Curves. Both operators use the `select_adjacent` function to (de)select adjacent points.
Pull Request #104626
Code to set the dragging data for a button was mostly duplicated, they
share it now. The followup commit also needs an easy way to reuse the
logic, which is possible now.
No longer use the existance of an image pointer inside the button, or
the the type of a button to decide if the entire button should be
draggable, or only its icon. This was rather sneaky, undocumented
behavior. Instead make this a proper option in the public UI API, and
enable it by default in specific cases to match the previous behavior.
This at least makes the behavior known and controllable in the API, and
not something that's just "secretly" done deep down in the button
handling code. I'd argue we should just use the entire button width by
default for dragging, but that would be a bigger change.
When the users click the "Mark as Asset" with the mouse hover the fake
user button, the button was not refreshed. In fact, the areas are not
listening to the "NC_ID NA_EDITED", which is the signal emitted after
an asset is marked/unmarked. Because of this, the areas aren't redrawn
(especially the ID buttons).
This little patch adds the event listening for the areas where this
problem is happening node editor and properties editor.
Pull Request #104694
After the removal of the "normal" attribute providers, we no longer
use the concept of read-only attributes. Removing this status simplifies
code, clarifies the design, and removes potentially buggy corner cases.
Pull Request #104795
The "normal" was added before fields existed because we needed a
way to expose the data to geometry nodes. It isn't really an attribute,
because it's read-only and it's derived rather than original data.
No features have relied on the "normal" attribute existing, except
for the corresponding column in the spreadsheet. However, the
column in the spreadsheet is also inconsistent, since it isn't an
attribute but looks just like the other columns. The normal is
always visible in the spreadsheet.
Pull Request #104795
* Fix#92539: Hard to read the breadcrumbs.
* Fix View Item active, hover, and text color (e.g. count numbers in the
Spreadsheet were almost unreadable).
* Fix mismatching node type colors with the default theme.
Blender Light is meant to be simply a brighter version of the default,
so screenshots and tutorials can be followed with both themes.
* Use the same outline color for widgets, so they match when aligned in a row.
* Make panels standout (not fully transparent), like in the default theme.
The active tools in `_defs_curves_sculpt` don't use names that are
exactly the same as the corresponding brush name with "builtin_brush."
at the beginning, instead they use more standard identifiers without
capitals or spaces.
The "brush_select" utility operator assumed the names matched though.
That can be fixed by manually mapping the brushes to the active tools.
Pull Request #104792
The keymap name in `WM_keymap_guess_from_context` didn't match the
name of the keymap in the Blender default keymap (`km_sculpt_curves`).
Fix by changing the utility function to match the keymap name.
Before right clicking on any tool in curves sculpt mode gave an assert,
now it shows a context menu.
Pull Request #104791
In BKE_screen_area_map_find_area_xy (find a ScrArea by 2D location),
ignore edges by using screen verts instead of totrct
Differential Revision: blender/blender#104680
Reviewed by Brecht Van Lommel
Lookup cache was not invalidated, to update attached effects position, a handle
of a input strip is touched.
To update attached effects, currently the code only does that when strip
position is changed. This is, because effect strip updating is done internally
in sequencer module code and ideally shouldn't be done at all. A TODO comment
with further explanation is added.
On the Windows platform allow Blender windows to be created that are
spread over multiple adjacent monitors.
---
On Windows we are quite feature-complete and stable for the creation and placement of multiple (non-temp) Blender windows. We correctly do so across multiple monitors no matter their arrangement, resolution, and scale.
However, there is another way that Blender could use multiple monitors - suggested by a core dev - which is to size a window so that it comprises multiple monitors. There are some advantages to this way of working because the one window remains constantly active and in focus. It also allows a single region (like a node editor) to be as large as possible.
But this way of working is not currently possible. That is because during window creation we constrain them to fit within the confines of the nearest single monitor. This has mostly been done for simplicity and safety. We don't want to restore a saved window to a position where it cannot be seen or used.
This patch addresses that. It allows windows to span multiple monitors, and does so safely by constraining the four corners of the window to be within the working area of any active monitor. This means it allows the creation of single windows as shown below in blue (left two), but does not allow the one in orange (right):
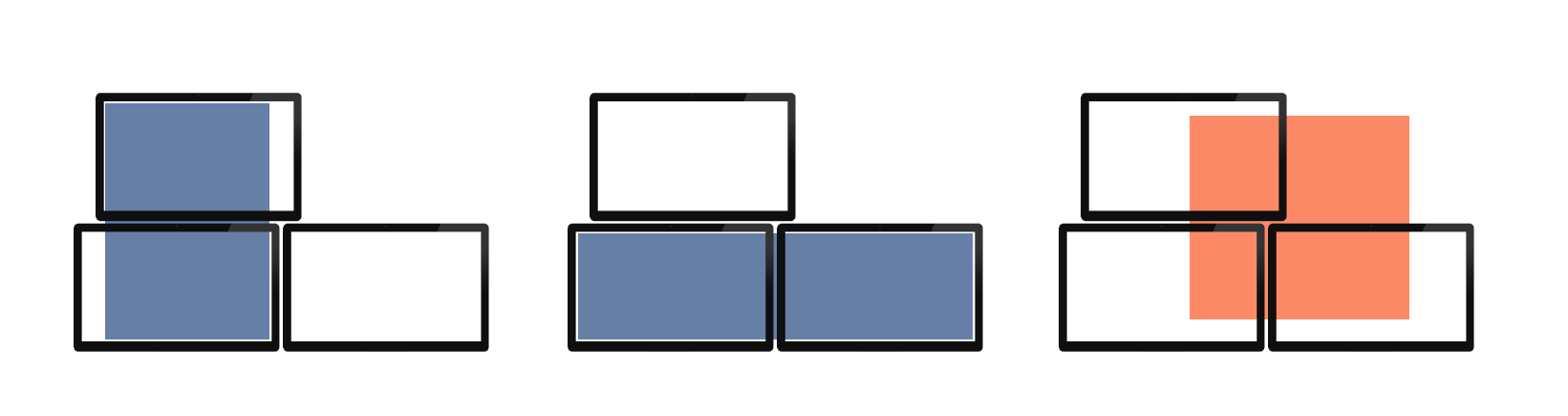
Note this has been previously (before gitea) reviewed and approved by Brecht.
Co-authored-by: Harley Acheson <harley.acheson@gmail.com>
Pull Request #104438
Avoid running out of attributes when multiple material slots use the same one.
Cleanup:
Removes the return value from drw_attributes_add_request since it shouldn't be modified afterward and it's never used.
Avoid making copies of DRW_AttributeRequest in drw_attributes_has_request.
Co-authored-by: Miguel Pozo <pragma37@gmail.com>
Pull Request #104709
Now that the UV map names are read from the evaluated mesh the names of
the anonymous layers would show up in the UV Map node and be accessible
via the python interface.
This changes the collection definition to skip anonymous layers.
Pull Request #104783
Instead of retrieving which attributes to transfer from the geometry set
which exists at a different abstraction level, get them from accessors
directly with a newer utility function. This removes boilerplate code
and makes the logic clearer for a future even more generic attribute
propagation API.
The evaluated positions cache can live longer than a specific
`CurvesGeometry`, but for only-poly curves, it pointed to the positions,
which are freed when the curves are. Instead, use the same pattern
as the evaluated offsets and don't store the positions span, just return
it when retrieving evaluated positions.
The evaluated positions cache can live longer than a specific
`CurvesGeometry`, but for only-poly curves, it pointed to the positions,
which are freed when the curves are. Instead, use the same pattern
as the evaluated offsets and don't store the positions span, just return
it when retrieving evaluated positions.
There are known bugs in HIP compiler that are causing random build failures
when making changes to the Cycles kernel. This is preventing developers from
efficiently making improvements to Cycles.
For now Cycles AMD GPU rendering is disabled in Blender 3.6 until a good
solution is found, so that ongoing work like Principled v2 is not blocked.
We hope this can be resolved later on in the 3.6 release cycle.
Ref #104786
This reverts 1116d821dc and part of 5bac672e1a.
The solution was made specifically for the 3.5 release, to avoid
breaking other cases. The previous commit addressed the problem properly
by letting the general menu code align labels where needed.
Usually in Blender, we try to align the labels of items within a menu,
if necessary by adding a blank icon for padding. This wasn't done for
menus generated from enum properties (RNA or custom property enums). Now
we do it whenever there is at least one item with an icon.
Since the menu doesn't automatically align the labels like other menus
and pulldowns in Blender, I manually made them align using the blank
icon. However the menu button would also include this blank icon now.
This is a specific fix for the 3.5 release. In the main branch I will
replace it with proper support for automatically aligning labels in such
menus.
Since the menu doesn't automatically align the labels like other menus
and pulldowns in Blender, I manually made them align using the blank
icon. However the menu button would also include this blank icon now.
This is a specific fix for the 3.5 release. In the main branch I will
replace it with proper support for automatically aligning labels in such
menus.
* BLENDER_VERSION_CYCLE set to beta
* Update pipeline_config.yaml to point to 3.5 branches and svn tags
* Update and uncomment BLENDER_VERSION in download.cmake
Usually when a menu item displays an icon, we indent all other items
with an empty icon so items align nicely. Now with more built-in asset
libraries (the new "Essentials" library), this inconsistency becomes
more apparent.
Also add a separator line between the "All" asset library and the
others, makes the menu look more organized.
The Preferences for asset libraries are becoming more than a simple name
+ path. E.g. there is now an Import Method options, and we previously
also considered a Relative Paths option (which we may still want to
add). The previous UI, while consistent with the Auto Run Python Scripts
UI isn't well suited for less than trivial cases. Using UI lists makes
the UI more scalable and follows usual list UI patterns more. There is
also more space for the path button now.
Part of #104686.
The default import method for an asset library can now be determined in
the Preferences. The Asset Browser has a new "Follow Preferences" option
for the importing. The essentials asset library still only uses "Append
(Reuse Data)".
This is part of #104686, which aims at improving the import method
selection, especially for the introduction of the new essentials library
(which doesn't support certain import methods). Further changes are
coming to improve the UI, see #104686.
Pull Request: #104688
The quick fur operator now uses the new hair system. It adds a new
curves object for every selected mesh, and adds geometry nodes
modifiers from the essentials assets that generate curves. A few
settings are exposed in the redo panel, including an option for whether
to apply the modifier to generate the initial curves so that there is
original editable data.
The point of the operator is to give people a sense of how to use the
node groups and to give a very fast way to build a basic setup for
further tweaking.
Pull Request #104764
Use the right hand side selection, as it fits the typical workflow
the best.
Arguably, the same would need to be done for the k-shortcut, but
that is another issue to be tackled. As well as making the selection
active.
Pull Request #104777
We (Dalai, Hans, Falk, Simon and me) decided that the curves edit mode
is useful enough to justify moving it out of experimental now. So far it
supports the following features:
* Various selection tools. The selections are synced with sculpt mode.
* Transform tools.
* Delete curves/points.
More functionality of the old curve edit mode will be ported over in
future releases.
This implements the delete operator in curves edit mode. The behavior
is similar to the delete operator in the edit mode of legacy curves,
i.e. it's actually dissolving and doesn't split curves. This is also
the behavior that we generally want for the hair use case.
The operator is added to the `Curves` menu and can be accessed via
the keyboard using `X` or `Del`.
Pull Request #104765
This adds a new `Curve Falloff` popover to the comb brush tool settings.
The curve control allows changing the brush weight along the curve to
e.g. affect the tip more than the root. This is a relative way to get
something like stiffness for short hair.
This functionality could potentially be added to some other brushes,
but the comb brush is the most important one, so that is added first.
I did add the buttons add the buttons to choose a curve map preset.
However, I did not add the preset dropdown, because that just adds
some unnecessary complexity in the code now and is redundant.
Pull Request #104589
This patch adds a simple operator to set values of the active
attribute for the selected element. The aim is to give simple control
over attribute values in edit mode rather than to provide the fastest
workflow for most cases. Eventually this operator might be less
important compared to more advanced attribute editing tools, but for
now, exposing a little bit of functionality is low hanging fruit and
will help to see the possibilities.
The implementation mostly consists of boilerplate to register the
necessary property types for the operator and draw their UI.
Beyond that, we just loop over selected elements and set a value.
Pull Request #104426
Caused by strips being flagged for removal, but the flag was never
cleared. As far as I can tell, this issue is not reproducible anymore,
but there may be files with this flag still set.
overlay_uniform_color_clipped was inheriting from overlay_depth_only, which doesn't
make much sense.
I've changed it to inherit from overlay_uniform_color instead, which is consistent
with other \*\_clipped variants of shaders.
Pull Request #104761
Certain material node graphs can be very expensive to run. This feature aims to produce secondary GPUPass shaders within a GPUMaterial which provide optimal runtime performance. Such optimizations include baking constant data into the shader source directly, allowing the compiler to propogate constants and perform aggressive optimization upfront.
As optimizations can result in reduction of shader editor and animation interactivity, optimized pass generation and compilation is deferred until all outstanding compilations have completed. Optimization is also delayed util a material has remained unmodified for a set period of time, to reduce excessive compilation. The original variant of the material shader is kept to maintain interactivity.
Also adding a new concept to gpu::Shader allowing assignment of a parent shader from which a shader can pull PSO descriptors and any required metadata for asynchronous shader cache warming. This enables fully asynchronous shader optimization, without runtime hitching, while also reducing runtime hitching for standard materials, by using PSO descriptors from default materials, ahead of rendering.
Further shader graph optimizations are likely also possible with this architecture. Certain scenes, such as Wanderer benefit significantly. Viewport performance for this scene is 2-3x faster on Apple-silicon based GPUs.
Authored by Apple: Michael Parkin-White
Ref T96261
Pull Request #104536
The logic for looping over imported OBJ faces and checking whether any
of them are "invalid" (duplicate vertices) was wrongly skipping
validation of the next face right after some invalid face. It
was the previously invalid face, moving the last into its place,
but then the loop was incrementing the face index and that just-moved
face was not properly validated.
Fixes#104593 - importing attached obj file (which contains some faces
that have duplicate indices). Added test coverage with a much smaller
obj file.
When the attribute doesn't exist, the node should give the default
of 12, as defined by the accessor method for `bke::CurvesGeometry`.
Pull Request #104674
This better aligns with OSX/Linux warnings.
Although `__pragma(warning(suppress:4100))` is not the same as
`__attribute__((__unused__))` in gcc (which only affects the attribute
instead of the line), it still seems to be better to use it than to
hide the warning entirely.
As described in #104171, add an operator that creates a new node group
that contain the current node group and named attribute nodes to deal
with the outputs. This saves manual work when moving a high-level
modifier to the node editor for better procedural control.
Pull Request #104546
This adds a new overlay for curves sculpt mode that displays the curves that the
user currently edits. Those may be different from the evaluated/original curves
when procedural deformations or child curves are used.
The overlay can clash with the evaluated curves when they are exactly on top of
each other. There is not much we can do about that currently. The user will have
to decide whether the overlay should be shown or not on a case-by-case basis.
Pull Request #104467
This renames `data` and `color` to `selection`. This is better because
it's actually what the corresponding buffers contain. Using this
more correct name makes sharing vertex buffers between different
gpu batches for different shaders easier.
The "current file" mode is only useful when creating new assets.
However, the far more common use case and the one that should require
fewer steps is to use existing assets.
There is a risk that this causes freezing if the file browser preview
caching does not work properly. So we'll have to keep an eye on the bug
tracker to see if this is an issue in practice.
Pull Request #104749
This patch adds an "Essentials" asset library that is bundled with Blender.
Also see #103620. At build time, the `lib/assets/publish` folder is copied
to `datafiles/assets` in the build directory.
In the UI, the "Essentials" library can be accessed like other custom asset
libraries with the exception that assets from that library cannot be linked.
The immediate impact of this is that Blender now comes with some geometry
node groups for procedural hair grooming.
Pull Request #104474
The OBJ spec (page B1-17) allows "l" entries to specify
polylines with more than 2 vertices, optionally with texture
coordinates.
Previously, only the first 2 vertices of each polyline
were read and added as loose edges, failing when texture
coordinates were present.
This adds support for proper polylines, reading but ignoring
texture coordinates.
Pull Request #104503
In 161908157d we moved all warnings
coming out of the library folder to /W0 as many of them do not follow
our code-style nor can we force them to.
When i made this change, i took `/external:templates-` to mean
"and that goes for you too, templates" and it decisively does the
opposite leading to /W3 warnings coming out of openvdb
This change removes the flag as it should have never have been added
in the first place.
Sculpt: Added vector displacement for the sculpting draw brush (area plane mapping only for now)
Vector displacement maps (VDM) provide a way to create complex displacements that can have overhangs in one brush dab.
This is unlike standard displacement with height maps that only displace in the normal direction.
Forms like ears, curled horns, etc can be created in one click if VMDs are used.
There is a checkbox on the draw brush in the texture settings "Vector Displacement" that enables/disables this feature.
Technical description: The RGB channels of a texture in a brush stroke are read and interpreted as individual vectors, that are used to offset vertices.
As of now, this is only working for the draw brush using the area plane mapping. Symmetry and radial symmetry are working.
A few things to consider when making VD-Maps:
* UVs need to stay intact for the bake mesh (e.g. voxel remeshing can't be used to create VD Meshes)
* When exporting a VD Map it should be in the file format OpenEXR (for positive and negative floating point values).
* Export resolution can be 512x512 or lower (EXR files can get very large, but VDM brushes don't need a high resolution)
And when using them:
* Inside Blender clamping needs to be unchecked on the texture
* The brush falloff should be set to constant (or nearly constant)
This patch was inspired by this [right-click-select proposal](https://blender.community/c/rightclickselect/WqWx/) Thanks for the post!
(Moved [this patch](https://archive.blender.org/developer/D17080) to here.)
Co-authored-by: Robin Hohnsbeen <robin@hohnsbeen.de>
Pull Request #104481
Curve type counts are updated eagerly but it was missing in this
node leading to a crash further down the line where the counts
were expected to be correct.
`MEM_delete()` is designed for type safe destruction and freeing, void
pointers make that impossible.
Was reviewing a patch that was trying to free a C-style custom data
pointer this way. Apparently MSVC compiles this just fine, other
compilers error out. Make sure this is a build error on all platforms
with a useful message.
The Volume property of the Maintain Volume constraint was marked as a
distance, which made it confusing--especially with non-metric units.
The volume can actually be understood as a factor of the initial
volume, so it should be dimensionless.
Additionally, the volume had a range of 0.001 to 100.0. This is wide
enough in most cases, but sometimes you may need to go orders of
magnitude higher or lower to consider vast or thin objects, and there
should be no drawback to extending the limits, provided they stay
positive.
Pull Request #104489
The proper fix (bb9eb262d4) caused compilation problems with HIP, so we're
delaying it until 3.6.
To fix the original bug report (#104586), this is a quick workaround that'll
hopefully not upset the compiler.
Pull Request #104723
A properly authored USD file will have the extent attribute authored on all prims conforming to UsdGeomBoundable.
This cached extent information is useful because it allows the 3D range of prims to be quickly understood without reading potentially large arrays of data. Note that because the shape of prims may change over time, extent attributes are always evaluated for a given timecode.
This patch introduces support for authoring extents on meshes and volumes during export to USD.
Because extents are common to multiple kinds of geometries, the main support for authoring extents has been placed in USDAbstractWriter, whose new author_extent method can operate on any prim conforming to pxr::UsdGeomBoundable. The USD library already provides us the code necessary to compute the bounds for a given prim, in pxr::UsdGeomBBoxCache::ComputeLocalBound.
Note that not all prims that are imageable are boundable, such as transforms and cameras.
For more details on extents, see https://graphics.pixar.com/usd/release/api/class_usd_geom_boundable.html#details.
Note that when new types of geometries are introduced, such as curves in https://developer.blender.org/D16545, we will need to update the USD writer for that geometry such that it calls this->author_extent.
Update on Feb 2: This patch has been updated to include a unit test to ensure authored extents are valid. This test requires new test assets that will need to be submitted via svn. The test assets are attached in the d16837_usd_test_assets.zip file. To use, unzip and merge the contents of this zip into the lib/tests/usd folder.
This unit test also addresses #104269 by validating compliance of exported USD via UsdUtils.ComplianceChecker.
Pull Request #104676
Use a MAKE wrapper for 'make deps' on Linux that ensures dependencies
are built one at a time. This is preferable because building many
dependencies at once made troubleshooting impractical and had the
downside that large deps such as LLVM would bottleneck on a single core.
This may be used for macOS, so far it's only tested on Linux.
- Correct broken link for undocumented modules.
Point to the contributing page, it seems #51062 was lost with the
GITEA task migration.
- Correct Blender Version link to the SHA1.
Matching the RNA id's to the search pattern is slow because
of the function `fnmatchcase`. This patch first checks the string
prefix without any special characters used by fnmatch,
if the `startswith` check fails, there is no need to check `fnmatchcase`.
Before the optimization, an online manual lookup took about 400ms
which is quite noticeable, with this patch applied it's under 10ms.
Ref !104581.
The internal compiler error appears to be gone. Unclear why it appeared in the
first place and why it's gone now. Just random kernel code changes causing it.
Pull Request #104719
- Rename roughness variables for more clarity - before, the SVM/OSL code would
set s and v to the linear roughness values, and the setup function would over-
write them with the distribution parameters. This actually caused a bug in the
albedo code, since it intended to use the linear roughness value, but ended up
getting the remapped value.
- Deduplicate the evaluation and sample functions. Most of their code is the
same, only the middle part is different.
- Changed albedo computation to return the sum of the intensities of the four
BSDF lobes. Previously, the code applied the inverse of the color->sigma
mapping from the paper - this returns the color specified in the node, but
for very dark hair (e.g. when using the Melanin controls) the result is
extremely low (e.g. 0.000001) despite the hair still reflecting a significant
amount of light (since the R lobe is independent of sigma). This causes issues
with the light component passes, so this change fixes#104586.
- There's quite a few computations at the start of the evaluation function that
are needed for sampling, evaluation and albedo computation, but only depend on
the view direction. Therefore, just precompute them - we still have space in
PrincipledHairExtra after all.
- Fix a tiny bug - the direction sampling code did not account for the R lobe
roughness modifier.
Pull Request #104669
In order to experiment with different storage types for `DRW_Attributes`
and for general cleanup (see #103343). Also move a curves header to C++.
Pull Request #104716
The existing logic to copy `BMesh` custom data layers to `Mesh`
attribute arrays was quite complicated, and incorrect in some cases
when the source and destinations didn't have the same layers.
The functions leave a lot to be desired in general, since they have
a lot of redundant complexity that ends up doing the same thing for
every element.
The problem in #104154 was that the "rest_position" attribute overwrote
the mesh positions since it has the same type and the positions weren't
copied. This same problem has shown up in boolean attribute conversion
in the past. Other changes fixed some specific cases but I think a
larger change is the only proper solution.
This patch adds preprocessing before looping over all elements to
find the basic information for copying the relevant layers, taking
layer names into account. The preprocessing makes the hot loops
simpler.
In a simple file with a 1 million vertex grid, I observed a 6%
improvement animation playback framerate in edit mode with a simple
geometry nodes modifier, from 5 to 5.3 FPS.
Fixes#104154, #104348
Pull Request #104421
Don't crash on nonexisting uv selection layers. Add an assert
because for now it is a bug if they don't exist. But when converting
back to Mesh it is preferable to accept in release mode, as opposed to
crashing.
Pull Request #104600
When generating a Mesh from a BMesh the uv map bool layers are not
copied if all elements are false. To suppress the copying the flag
CD_FLAG_NOCOPY is set in the layer flags. However these layers *do*
need to be copied to other BMeshes (for example undo steps). So we
need to clear them afterwards.
This commit adds the ability to import USD Shape primitives (Gprims).
They are imported as Blender Meshes using the USD API to convert, so
that they appear the same as they would in other applications. USD
Shapes are important in many workflows, particularly in gaming, where
they are used for stand-in geometry or for collision primitives.
Pull Request #104707
The issue was caused by rather recent refactor in 7dea18b3aa.
The root of the issue lies within the fact that the optical center was updated
on the Blender side after the solution was run. There was a mistake in the code
which double-corrected for the pixel aspect ratio.
Added a comment in the code about this, so that it does not look suspicious.
Pull Request #104711
`CTX_wm_operator_poll_msg_set()` is covered by the translation script
and always translates these strings. Checked with Bastien, he prefers
not having the redundancy here.
## Cleanup: Refactor NLATrack / NLAStrip Remove
This PR adds 3 new methods:
* BKE_nlatrack_remove_strip
* BKE_nlastrip_remove
* BKE_nlastrip_remove_and_free
These named BKE methods are really just replacements for BLI_remlink, but with some added checks, and enhanced readability.
Co-authored-by: Nate Rupsis <nrupsis@gmail.com>
Pull Request #104437
Send a notification and tag for an update even if the selection doesn't
exist, which is still necessary for drawing that depends on the
selection domain.
As a side effect of this change, more resolution divisions are now available.
Before this patch the possible resolution divisions were all powers of two.
Now the possible resolution divisions are the multiples of pixel_size.
This increase in possible resolution divisions is the same idea proposed in https://archive.blender.org/developer/D13590.
In that patch there were concerns that this will increase the time between a user navigating
and seeing the 1:1 render. To my knowledge this is a non-issue and there should be
little to no increase in time between those two events.
Pull Request #104450
This is needed to be able to query asset library information from an
asset. This again is relevant especially for the "All" asset library,
where you can't just directly access the library itself, which is
different for different assets.
The current design is that an asset representation is owned by exactly
one asset library, so having this pointer is perfectly compatible with
the design.
Reviewed by: Julian Eisel
This replaces `GPU_SHADER_3D_POINT_FIXED_SIZE_VARYING_COLOR` by
GPU_SHADER_2D_POINT_UNIFORM_SIZE_UNIFORM_COLOR_OUTLINE_AA`.
None of the usage made sense to not use the AA shader.
Scale the point size to account for the rounded shape.
Ref #104280
The scaling of area light / spot light blend was wrong because it is
calculated for pivot at the edges. The new implementation in theory
works for all `abs(pivot) <= 0.5f`, although we only have -0.5, 0, and
0.5.
- Axis constraint for box cage was only applied when there is translate
flag, now the same logic is applied regardless of the translate flag,
this means when dragging the edge, the scaling in the other axis stays
the same; when dragging the corners, it applies free-form scaling.
- Due to the existence of margin, `data->orig_mouse` does not lie
exactly on the boundary. Using that value to compute the scaling causes
the error to accumulate over distance. The new implementation uses the
original dimension of the object instead, and only uses
`data->orig_mouse` to determine the side of the original cursor relative
to the pivot.
- For circular gizmo with unsigned scaling, the gizmo only follow the
cursor exactly when the cursor stays in the original quadrant, otherwise
it's hard to handle the logic when we should clamp the scaling.
The buttons of enum context menus are of type `UI_BUT_ROW`. They
are part of the set of buttons we create underline shortcuts for in
`ui_menu_block_set_keyaccels`.
But since they weren't handled in `ui_handle_button_activate_by_type`,
pressing the underline shortcuts didn't do anyting in those cases.
Co-authored-by: Leon Schittek <leon.schittek@gmx.net>
Co-authored-by: Brecht Van Lommel <brecht@noreply.localhost>
Pull Request #104433
Currently the passepartout color is hardcoded to black. While a
sensible default for cinema, it may make less sense for other media,
whether video, print, web, etc. It greatly affects viewing conditions
of the image and should be user selectable, much like painting
programs allow.
Pull Request #104486
Don't create caps when using cyclic profile splines with two or fewer
points.
This case wasn't handled, yet, leading to invalid meshes or crashes.
Co-authored-by: Leon Schittek <leon.schittek@gmx.net>
Pull Request #104594
Vulkan has a pluggable memory allocation feature, which allows internal
driver allocations to be done by the client application provided
allocator. Vulkan uses this for more client application allocations
done inside the driver, but can also do it for more internal oriented
allocations.
VK_ALLOCATION_CALLBACKS initializes allocation callbacks for host allocations.
The macro creates a local static variable with the name vk_allocation_callbacks
that can be passed to vulkan API functions that expect
const VkAllocationCallbacks *pAllocator.
When WITH_VULKAN_GUARDEDALLOC=Off the memory allocation implemented
in the vulkan device driver is used for both internal and application
oriented memory operations.
For now this would help during the development of Vulkan backend to
detect hidden memory leaks that are hidden inside the driver part
of the stack. In a later stage we need to measure the overhead and
if this should become the default behavior.
Pull Request #104434
The GPU module has 2 different styles when reading back data from
GPU buffers. The SSBOs used a memcpy to copy the data to a
pre-allocated buffer. IndexBuf/VertBuf gave back a driver/platform
controlled pointer to the memory.
Readback is done for test cases returning mapped pointers is not safe.
For this reason we settled on using the same approach as the SSBO.
Copy the data to a caller pre-allocated buffer.
Reason why this API is currently changed is that the Vulkan API is more
strict on mapping/unmapping buffers that can lead to potential issues
down the road.
Pull Request #104571
Keep using the 3 evaluations dF_branch method for the Displacement output.
The optimized 2 evaluations method used by node_bump is now on its own macro (dF_branch_incomplete).
displacement_bump modifies the normal that nodetree_exec uses, so even with a refactor it wouldn’t be possible to re-use the computation anyway.
Using larger integer types allows for more efficient code, because we
can use the hardware better. Instead of working on individual bytes,
the code can now work on 8 bytes at a time. We don't really benefit
from this immediately but I'm planning to implement some more optimized
bit vector operations for #104629.
Pull Request #104658
Add a test to address the issue raised in #103913, where zero area
triangles could be created from polygons that have co-linear edges
but were not degenerate.
Since USD is no longer statically linked these linker tricks
are no longer needed.
Co-authored-by: Ray Molenkamp <github@lazydodo.com>
Pull Request #104627
When building a node group that's meant to be used directly in the
node editor as well as in the modifier, it's useful to be able to have
some inputs that are only meant for the node editor, like inputs that
only make sense when combined with other nodes.
In the future we might have the ability to only display certain assets
in the modifier and the node editor, but until then this simple solution
allows a bit more customization.
Pull Request #104517
During hair grooming in curves sculpt mode, it is very useful when hair strands
are prevented from intersecting with the surface mesh. Unfortunately, it also
decreases performance significantly so we don't want it to be turned on all the time.
The surface collision is used by the Comb, Pinch and Puff brushes currently.
It can be turned on or off on a per-geometry basis.
The intersection prevention quality of this patch is not perfect yet. This can
be improved over time using a better solver. Overall, perfect collision detection
at the cost of bad performance is not necessary for interactive sculpting,
because the user can fix small mistakes very quickly. Nevertheless, the quality
can probably still be improved significantly without too big slow-downs depending
on the use case. This can be done separately from this patch.
Pull Request #104469
Previously, the node used the "true" normal of every looptri. Now it uses the
"loop normals" which includes e.g. smooth faces and custom normals. The true
normal can still be used on the points by capturing it before the Distribute node.
We do intend to expose the smooth normals separately in geometry nodes as well,
but this is an important first step.
It's also necessary to generate child hair between guide hair strands that don't
have visible artifacts at face boundaries.
For perfect backward compatibility, the node still has a "Legacy Normal" option
in the side bar. Creating the exact same behavior with existing nodes isn't
really possible unfortunately because of the specifics of how the Distribute
node used to compute the normals using looptris.
Pull Request #104414
CustomData layer names should not be written except via the CusomData
api. Therefore use const char * instead of char * when referencing the
layer name.
Pull Request #104585
Avoid computing the non-derivative height twice.
The height is now computed as part of the main function, while the height at x and y offsets are still computed on a separate function.
The differentials are now computed directly at node_bump.
Co-authored-by: Miguel Pozo <pragma37@gmail.com>
Pull Request #104595
This adds a `select_lasso` and a `select_circle` function for the Curves object. It is used in the `view3d_lasso_select` and `view3d_circle_select` operator.
Co-authored-by: Falk David <falkdavid@gmx.de>
Pull Request #104560
This adds a new `select_linked` function that selects all the points
on a curve if there is at least one point already selected.
This also adds a keymap for the operator.
Co-authored-by: Falk David <falkdavid@gmx.de>
Pull Request #104569
Add `contains_group` method in python api for `NodeTree` type, cleanup
`ntreeHasTree` function, reuse `ntreeHasTree` in more place in code.
The algorithm has been changed to not recheck trees by using set.
Performance gains from avoiding already checked node trees:
Based on tests, can say that for large files with a huge number
of trees, the response speed of opening the search menu in the
node editor increased by ~200 times (for really large projects
with 16 individual groups in 6 levels of nesting). Group insert
operations are also accelerated, but this is different in some cases.
Pull Request #104465
This reverts commit aab707ab70.
A different solution to the submodule problem is being considered in #104573.
Revert to the previous behavior that developers are familiar with for now.
This just adds `threading::parallel_for` and `threading::parallel_invoke` in a few
places where it can be added trivially. The run time of the `separate_geometry`
function changes from 830 ms to 413 ms in my test file.
Pull Request #104563
Using callback functions didn't scale well as more arguments are added.
It got very confusing when to pass tehmarguments weren't always used.
Instead use a `FunctionRef` with indices for arguments. Also remove
unused edge arguments to topology mapping functions.
Adds an experimental option under "New Features" in preferences,
which enables visibility of the new Volume Nodes.
Right now this option does nothing but will be used during development.
See #103248
Pull Request #104552
Because of T95965, some attributes are stored as generic attributes
in Mesh but have special handling for the conversion to BMesh.
Expose a function to tell whether certain attribute names are handled
specially in the conversion, and refactor the error checking process
to use it. Also check for generic attributes on the face domain which
wasn't done before.
Author: Hans Goudey
Reviewed By: Joseph Eagar
Co-authored-by: Joseph Eagar <joeedh@gmail.com>
Pull Request #104567
When merging two gpencil layers, if the destination layer had a keyframe
where the source layer did not, strokes of the previous keyframe
in source layer were lost in that frame.
This happened because the merge operator was looping through
frames of the source layer and appending strokes in the
corresponding destination layer, but never completing
other frames than the ones existing in the source layer.
This patch fixes it by first adding in source layer
all frames that are in destination layer.
Co-authored-by: Amelie Fondevilla <amelie.fondevilla@les-fees-speciales.coop>
Pull Request #104558
When the sequencer is empty (i.e., there are no sequences),
we would have the deselect_all variable set to true called
ED_sequencer_deselect_all to select any existing sequences.
Ref !104453
Box-Selecting channels in the dope sheet with click-drag was no longer possible as of Blender 3.2
Due to the removal of tweak events the box select operator was always shadowed by the click operator.
Original Phabricator discussion here: https://archive.blender.org/developer/D17065
Use `WM_operator_flag_only_pass_through_on_press` on click operator to fix it
Co-authored-by: Christoph Lendenfeld <chris.lenden@gmail.com>
Pull Request #104505
(Follow on from D17043)
On AMD Navi2 devices the MetalRT checkbox was not hooked up properly and had no effect. This patch fixes it.
Co-authored-by: Michael Jones <michael_p_jones@apple.com>
Pull Request #104520
- Avoid flooding the output with every match that succeeds.
- Report patterns listed in the manual that don't match anything in
Blender.
- Disable external URL lookups, this is too slow.
Instead use a LOCAL_PREFIX (a local build of the manual)
or skip the test.
Without this, every access to "language" would warn that the enum
value didn't match a value in the enum items.
This made the bl_rna_manual_reference.py test output practically
unusable.
The generator now skips these with a warning, they will need to be
corrected in the user manual.
This caused tests/python/bl_rna_manual_reference.py to fail looking
up URL's.
Move the function for getting the language code associated with the
user manual into a utility function (from the generated
rna_manual_reference.py).
This allows other parts of Blender to create a manual URL based on the
current locale preferences and environment.
Ref !104494
Documented all functions, adding use case and side effects.
Also replace the use of shortened argument name by more meaningful ones.
Renamed `GPU_batch_instbuf_add_ex` and `GPU_batch_vertbuf_add_ex` to remove
the `ex` suffix as they are the main version used (removed the few usage
of the other version).
Renamed `GPU_batch_draw_instanced` to `GPU_batch_draw_instance_range` and
make it consistent with `GPU_batch_draw_range`.
When nodes are copied to the clipboard, they don't need their declaration.
For nodes with dynamic declaration that might depend on the node tree itself,
the declaration could not be build anyway, because the node-clipboard does
not have a node tree.
Pull Request #104432
Add a new node that groups faces inside of boundary edge regions.
This is the opposite action as the existing "Face Group Boundaries"
node. It's also the same as some of the "Initialize Face Sets"
options in sculpt mode.
Discussion in #102962 has favored "Group" for a name for these
sockets rather than "Set", so that is used here.
Pull Request #104428
Currently there's no way to assign a geometry node group from the asset
browser to an object as a modifier without first appending/linking it
manually. This patch adds a drag and drop operator that adds a new
modifier and assigns the dragged tree.
Pull Request #104430
As described in #95966, replace the `ME_EDGEDRAW` flag with a bit
vector in mesh runtime data. Currently the the flag is only ever set
to false for the "optimal display" feature of the subdivision surface
modifier. When creating an "original" mesh in the main data-base,
the flag is always supposed to be true.
The bit vector is now created by the modifier only as necessary, and
is cleared for topology-changing operations. This fixes incorrect
interpolation of the flag as noted in #104376. Generally it isn't
possible to interpolate it through topology-changing operations.
After this, only the seam status needs to be removed from edges before
we can replace them with the generic `int2` type (or something similar)
and reduce memory usage by 1/3.
Related:
- 10131a6f62
- 145839aa42
In the future `BM_ELEM_DRAW` could be removed as well. Currently it is
used and aliased by other defines in some non-obvious ways though.
Pull Request #104417
This adds a `select_box` function for the `Curves` object. It is used in the `view3d_box_select` operator.
It also adds the basic selection tools in the toolbar of Edit Mode.
Authored-by: Falk David <falkdavid@gmx.de>
Pull Request #104411
The required version numbers for various devices was hardcoded in the
UI messages. The result was that every time one of these versions was
bumped, every language team had to update the message in question.
Instead, the version numbers can be extracted, and injected into the
error messages using string formatting so that translation updates
need happen less frequently.
Pull Request #104488
`bAnimContext` had a float property called `yscale_fac` that was used to define the height of the keyframe channels.
However the property was never set, only read so there really is no need to have it in the struct.
Moreover it complicated getting the channel height because `bAnimContext` had to be passed in.
Speaking of getting the channel height. This was done with macros. I ripped them all out and replaced them with function calls.
Originally it was introduced in this patch: https://developer.blender.org/rB095c8dbe6919857ea322b213a1e240161cd7c843
Co-authored-by: Christoph Lendenfeld <chris.lenden@gmail.com>
Pull Request #104500
This is used for most Python release builds and has been reported to
give a modest 5-10% speedup (depending on the workload).
This could be enabled on macOS too but needs to be tested.
Blender was reporting that the GPU_TEXTURE_USAGE_HOST_READ wasn't set.
This is used to indicate that the textures needs to be read back to
CPU. Textures that don't need to be read back can be optimized by the
GPU backend.
Found during investigation of #104282.
- Use bpy.utils.execfile instead of importing then deleting from
sys.modules.
- Add a note for why keeping this cached in memory isn't necessary.
This has the advantage of not interfering with any scripts that import
`rna_manual_reference` as a module.
This allow to bypass all cost associated with shadow mapping.
This can be useful in certain situation, such as opening a scene on a
lower end system or just to gain performance in some situation (lookdev).
The merge with master updated the code to use the new matrix API. This
introduce some regressions.
For sunlights make sure there is enough tilemaps in orthographic mode
to cover the depth range and fix the level offset in perspective.
Implements virtual shadow mapping for EEVEE-Next primary shadow solution.
This technique aims to deliver really high precision shadowing for many
lights while keeping a relatively low cost.
The technique works by splitting each shadows in tiles that are only
allocated & updated on demand by visible surfaces and volumes.
Local lights use cubemap projection with mipmap level of detail to adapt
the resolution to the receiver distance.
Sun lights use clipmap distribution or cascade distribution (depending on
which is better) for selecting the level of detail with the distance to
the camera.
Current maximum shadow precision for local light is about 1 pixel per 0.01
degrees.
For sun light, the maximum resolution is based on the camera far clip
distance which sets the most coarse clipmap.
## Limitation:
Alpha Blended surfaces might not get correct shadowing in some corner
casses. This is to be fixed in another commit.
While resolution is greatly increase, it is still finite. It is virtually
equivalent to one 8K shadow per shadow cube face and per clipmap level.
There is no filtering present for now.
## Parameters:
Shadow Pool Size: In bytes, amount of GPU memory to dedicate to the
shadow pool (is allocated per viewport).
Shadow Scaling: Scale the shadow resolution. Base resolution should
target subpixel accuracy (within the limitation of the technique).
Related to #93220
Related to #104472
The previous change in the .gitmodules made it so the `make update`
rejects to do its thing because it now sees changes in the submodules
and rejected to update, thinking there are unstaged changes.
Ignore the submodule changes, bringing the old behavior closer to
what it was.
The meaning of the ignore option for submodules did change since our
initial Git setup was done: back then it was affecting both diff and
stage families of Git command. Unfortunately, the actual behavior did
violate what documentation was stating (the documentation was stating
that the option only affects diff family of commands). This got fixed
in Git some time after our initial setup and it was the behavior of the
commands changed, not the documentation. This lead to a situation when
we can no longer see that submodules are modified and staged, and it is
very easy to stage the submodules.
For the clarity: diff and status are both "status" family, show and
diff are "diff" family.
Hence this change: since there is no built-in zero-configuration way
of forbidding Git from staging submodules lets make it visible and
clear what the state of submodules is.
We still need to inform people to not stage submodules, for which
we can offer some configuration tips and scripts but doing so is
outside of the scope of this change at it requires some additional
research. Current goal is simple: make it visible and clear what is
going to be committed to Git.
This is a response to an increased frequency of incidents when the
submodules are getting modified and committed without authors even
noticing this (which is also a bit annoying to recover from).
Differential Revision: https://developer.blender.org/D13001
Subdivision surface efficiency relies on caching pre-computed topology
data for evaluation between frames. However, while eed45d2a23
introduced a second GPU subdiv evaluator type, it still only kept
one slot for caching this runtime data per mesh.
The result is that if the mesh is also needed on CPU, for instance
due to a modifier on a different object (e.g. shrinkwrap), the two
evaluators are used at the same time and fight over the single slot.
This causes the topology data to be discarded and recomputed twice
per frame.
Since avoiding duplicate evaluation is a complex task, this fix
simply adds a second separate cache slot for the GPU data, so that
the cost is simply running subdivision twice, not recomputing topology
twice.
To help diagnostics, I also add a message to show when GPU evaluation
is actually used to the modifier panel. Two frame counters are used
to suppress flicker in the UI panel.
Differential Revision: https://developer.blender.org/D17117
Pull Request #104441
The ear clipping method used by polyfill_2d only excluded concave ears
which meant ears exactly co-linear edges created zero area triangles
even when convex ears are available.
While polyfill_2d prioritizes performance over *pretty* results,
there is no need to pick degenerate triangles with other candidates
are available. As noted in code-comments, callers that require higher
quality tessellation should use BLI_polyfill_beautify.
Sockets after the geometry socket were ignored when cycling through
the node's output sockets. If there are multiple geometry sockets, the
behavior could still be refined probably, but this should at least make
basic non-geometry socket cycling work.
Now a single script to generate both links and release notes. It also includes
the issue ID for the LTS releases, so only the release version needs to be
specified.
Pull Request #104402
Minor change to [0], prefer calling em_setup_viewcontext,
even though there is no functional difference at the moment,
if this function ever performs additional operations than assigning
`ViewContext.em`, it would have to be manually in-lined in
`view3d_circle_select_recalc`.
[0]: 430cc9d7bf
Added missing documentation for `draw_cursor_add` and
`draw_cursor_remove` methods for `WindowManager`.
Differential Revision: https://developer.blender.org/D14860
Discard is not always treated as an explicit return and flow control can continue for required derivative calculations. This behaviour is different in Metal vs OpenGL. Adding return after discards ensures consistency in expectation as behaviour is well-defined.
Authored by Apple: Michael Parkin-White
Ref T96261
Reviewed By: fclem
Maniphest Tasks: T96261
Differential Revision: https://developer.blender.org/D17199
Host memory fallback in CUDA and HIP devices is almost identical.
We remove duplicated code and create a shared generic version that
other devices (oneAPI) will be able to use.
Reviewed By: brecht
Differential Revision: https://developer.blender.org/D17173
Straightforward port. I took the oportunity to remove some C vector
functions (ex: copy_v2_v2).
This makes some changes to DRWView to accomodate the alignement
requirements of the float4x4 type.
`9c14039a8f4b5f` broke blenlib tests in release builds, due to how
`EXPECT_BLI_ASSERT` works (in release builds it just calls the given
function, so if that crashes then the test fails).
For now remove that check in the test.
Remove the use of a separate contiguous positions array now that
they are stored that way in the first place. This allows removing the
complexity of tracking whether it is allocated and deformed in the
mesh modifier stack.
Instead of deferring the creation of the final mesh until after the
positions have been copied and deformed, create the final mesh
first and then deform its positions.
Since vertex and face normals are calculated lazily, we can rely on
individual modifiers to calculate them as necessary and simplify
the modifier stack. This was hard to change before because of the
separate array of deformed positions.
Differential Revision: https://developer.blender.org/D16971
When activating a rotation with the Transform gizmo for example, some
gizmos are hidden but they don't reappear when changing the mode.
Make sure the gizmos corresponding to the mode always reappear.
This patch optimises subsurface intersection queries on MetalRT. Currently intersect_local traverses from the scene root, retrospectively discarding all non-local hits. Using a lookup of bottom level acceleration structures, we can explicitly query only the relevant instance. On M1 Max, with MetalRT selected, this can give a render speedup of 15-20% for scenes like Monster which make heavy use of subsurface scattering.
Patch authored by Marco Giordano.
Reviewed By: brecht
Differential Revision: https://developer.blender.org/D17153
`em_setup_vivewcontext` cannot be used in this function now as it
expects `obedit` to be a mesh. It also duplicated the viewcontext init.
Instead `BKE_editmesh_from_object` is called only when type is a mesh.
Existing `BKE_main_namemap_destroy` is too specific when a entire Main
needs to have its namemaps cleared, since it would not handle the
Library ones.
While in regular situation current code is fine, ID management code that
may also edit linked data needs a wider, simpler clearing tool.
Current `BKE_id_remapper_add` would not replace an already existing
mapping rule, now `BKE_id_remapper_add_overwrite` allows that behavior
if necessary.
If identity pairs (i.e. old ID pointer being same as new one) was
forbidden, then this should be asserted against in code defining
remapping, not in code applying it.
But it is actually sometimes usefull to allow/use identity pairs, so
simply early-return on these instead of asserting.
The goal is to give technical artists the ability to optimize modifier usage
and/or geometry node groups for performance. In the long term, it
would be useful if Blender could provide its own UI to display profiling
information to users. However, right now, there are too many open
design questions making it infeasible to tackle this in the short term.
This commit uses a simpler approach: Instead of adding new ui for
profiling data, it exposes the execution-time of modifiers in the Python
API. This allows technical artists to access the information and to build
their own UI to display the relevant information. In the long term this
will hopefully also help us to integrate a native ui for this in Blender
by observing how users use this information.
Note: The execution time of a modifier highly depends on what other
things the CPU is doing at the same time. For example, in many more
complex files, many objects and therefore modifiers are evaluated at
the same time by multiple threads which makes the measurement
much less reliable. For best results, make sure that only one object
is evaluated at a time (e.g. by changing it in isolation) and that no
other process on the system keeps the CPU busy.
As shown below, the execution time has to be accessed on the
evaluated object, not the original object.
```lang=python
import bpy
depsgraph = bpy.context.view_layer.depsgraph
ob = bpy.context.active_object
ob_eval = ob.evaluated_get(depsgraph)
modifier_eval = ob_eval.modifiers[0]
print(modifier_eval.execution_time, "s")
```
Differential Revision: https://developer.blender.org/D17185
The `SNAP_FORCED` setting is set to the operation and not the snap
status.
Therefore, this option should not be cleared along with the other
statuses when resetting snapping.
Move then the location of this setting to `TransInfo::modifiers`.
BGL deprecation calls used to be reported on each use. As bgl calls
are typically part of a handler that is triggered at refresh this
could lead to overflow of messages and slowing down systems when
the terminal/console had to be refreshed as well.
This patch only reports the first 100 bgl deprecation calls. This
gives enough feedback to the developer that changes needs to be made
. But still provides good responsiveness to users when they have
such add-on enabled. Only the first frames can have a slowdown.
This patch adds two new kernels: SORT_BUCKET_PASS and SORT_WRITE_PASS. These replace PREFIX_SUM and SORTED_PATHS_ARRAY on supported devices (currently implemented on Metal, but will be trivial to enable on the other backends). The new kernels exploit sort partitioning (see D15331) by sorting each partition separately using local atomics. This can give an overall render speedup of 2-3% depending on architecture. As before, we fall back to the original non-partitioned sorting when the shader count is "too high".
Reviewed By: brecht
Differential Revision: https://developer.blender.org/D16909
This patch removes the option to select both AMD and Intel GPUs on system that have both. Currently both devices will be selected by default which results in crashes and other poorly understood behaviour. This patch adds precedence for using any discrete AMD GPU over an integrated Intel one. This can be overridden with CYCLES_METAL_FORCE_INTEL.
Reviewed By: brecht
Differential Revision: https://developer.blender.org/D17166
This patch fixes T103393 by undefining `__LIGHT_TREE__` on Metal/AMD as it has an unexpected & major impact on performance even when light trees are not in use.
Patch authored by Prakash Kamliya.
Reviewed By: brecht
Maniphest Tasks: T103393
Differential Revision: https://developer.blender.org/D17167
The merge down operator was sometimes copying the wrong frame, which altered the animation.
While merging the layers, it is sometimes needed to duplicate a keyframe,
when the lowest layer does not have a keyframe but the highest layer does.
Instead of duplicating the previous keyframe of the lowest layer, the code
was actually duplicating the active frame of the layer which was the current frame in the timeline.
This patch fixes the issue by setting the previous keyframe of the layer as its active frame before duplication.
Related issue: T104371.
Differential Revision: https://developer.blender.org/D17214
Mutex locks for manipulating GHOST_System::m_timerManager from
GHOST_SystemWayland relied on WAYLAND being the only user of the
timer-manager.
This isn't the case as timers are fired from
`GHOST_System::dispatchEvents`.
Resolve by using a separate timer-manager for wayland key-repeat timers.
Resolve a thread safety issue reported by valgrind's helgrind checker,
although I wasn't able to redo the error in practice.
NULL check on the key-repeat timer also needs to lock, otherwise it's
possible the timer is set in another thread before the lock is acquired.
Now all key-repeat timer access which may run from a thread
locks the timer mutex before any checks or timer manipulation.
There were two errors with the function used to convert face sets
to the legacy mesh format for keeping forward compatibility:
- It was moved before `CustomData_blend_write_prepare` so it
operated on an empty span.
- It modified the mesh when it's only supposed to change the copy
of the layers written to the file.
Differential Revision: https://developer.blender.org/D17210
Coded the RNA functions to only work with the preferences for the
start. But we actually don't have to care here if the libraries are
defined in the preferences or project.
Mostly this is about more cleanly separating between `BlenderProject`
and `ProjectSettings`. Overall this is a nice improvement I think, helps
readability of interfaces and implementation a lot.
The hint in the asset browser for when the selected library path doesn't
exists is updated to mention the project settings too, and there is a
button to open the project settings in the asset library section.
Default project name will just be the directory name. The default asset
library will be called "Project Library" and point to an `assets/`
directory inside the project root directory.
Looks just like the UI for setting up custom asset libraries in the
Preferences. However project asset libraries use paths relative to the
project root directory.
Had to do some changes to project data storage to avoid memory issues.
Looks a bit less nice, but doesn't mess with muscle memory as much,
since the Preferences used to be last in the menu. I for one kept
opening the wrong window :)
Disable the navigation and "Save Settings" buttons when there is no
active project.
The message saying that no project is loaded always shows up now, even
if the UI somehow displays a section that is not the "General" one.
The active project is determined via the path of the .blend file. So if
that changes (on write) or when a new .blend file is opend, the active
project is updated.
Some of the added tests require a latest checkout of the libraries SVN
repository (see rBL63043).
When unit testing on Unix with Windows style slashes, the project
directories would have the backslash in the name, rather than
recognizing it as nested directory. We could just expect native paths
only like most BLI functions, but it's not a big problem to just support
any format and just convert it internally. The most important part is
that the API defines well how it deals with the different formats, and
that this is unit tested. Ideally we'd have some path object type that
abstracts away the difference.
option(WITH_CYCLES_DEVICE_HIP"Enable Cycles AMD HIP support"ON)
option(WITH_CYCLES_HIP_BINARIES"Build Cycles AMD HIP binaries"OFF)
set(CYCLES_HIP_BINARIES_ARCHgfx1010gfx1011gfx1012gfx1030gfx1031gfx1032gfx1034gfx1035gfx1100gfx1101gfx1102CACHESTRING"AMD HIP architectures to build binaries for")
set(CYCLES_HIP_BINARIES_ARCHgfx900gfx906gfx90cgfx902 gfx1010gfx1011gfx1012gfx1030gfx1031gfx1032gfx1034gfx1035gfx1100gfx1101gfx1102CACHESTRING"AMD HIP architectures to build binaries for")
mark_as_advanced(WITH_CYCLES_DEVICE_HIP)
mark_as_advanced(CYCLES_HIP_BINARIES_ARCH)
endif()
@@ -625,8 +625,10 @@ mark_as_advanced(
# Vulkan
option(WITH_VULKAN_BACKEND"Enable Vulkan as graphics backend (only for development)"OFF)
option(WITH_VULKAN_GUARDEDALLOC"Use guardedalloc for host allocations done inside Vulkan (development option)"OFF)
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.