- "Lines" in the sense of number of lines
- "Number" can mean "amount, count" or "index, offset"
- "Second" can be an ordinal number or a unit
- "Root": add the brush curve to the "square root falloff" sense
- "Strip" can be a sequence or a type of hair rendering
- "Constant" in the sense of a value, for the Geometry Nodes add
submenu (#105447).
Additionally, extract:
- "Press a key" from the Keymap preferences.
- "MaskLayer", upon new mask layer creation
Ref #43295, #105447
While developing a new armature draw type, I was switching between
branches and opening the same test file. It would crash Blender because
it assumed that the `else` clause could only mean `(arm->drawtype ==
ARM_OCTA)`. This is now explicitly tested for.
The result is that an armature with unknown draw type is not drawn at
all, but I prefer that over either resetting the draw type to something
valid (thus altering the blend file) or downright crashing.
This was caused by an incorrect assumption in the solver:
It tries to solve both collision and length constraints simultaneously,
using the projected movement of a point as a slide direction along the surface.
This only works if the distance of the previous curve point to the surface
is less than the allowed segment length. Otherwise the segment will
exceed the allowed length even with zero slide and NaN values are computed.
The case of larger surface distance can occur if the previous segment
solve was already stretching the current segment and then the point
moves further away. In this case we can simply clamp the segment length
without violating the contact constraint.
Pull Request #105499
This was caused by an incorrect assumption in the solver:
It tries to solve both collision and length constraints simultaneously,
using the projected movement of a point as a slide direction along the surface.
This only works if the distance of the previous curve point to the surface
is less than the allowed segment length. Otherwise the segment will
exceed the allowed length even with zero slide and NaN values are computed.
The case of larger surface distance can occur if the previous segment
solve was already stretching the current segment and then the point
moves further away. In this case we can simply clamp the segment length
without violating the contact constraint.
Fixes#105467
Pull Request #105499
Some UI functions have a "translate" argument, which if set to False
specifies that the message is not to be translated. This sometimes
means that it was already translated beforehands.
But many messages were still getting extracted, sometimes twice in
different contexts. Some featured errors because the arguments of
various functions would be concatenated, such as:
```
col.label(text=iface_("Branch: %s") % bpy.app.build_branch.decode('utf-8', 'replace'), translate=False)
```
which would get extracted as:
```
msgid "Branch: %sutf-8replace"
```
Pull Request #105417
When investigating ID user-count issues, it wasn't clear how nodes
were meant to handle user-count for ID's. Specifically that the
initfunc should _not_ increment the ID's user count.
Doing such writes leaves dangling file in the installation directory which
then is packaged as well. Not only this makes it so a random file gets
packaged for installation, it also makes notarization process to fail because
of not-so-clear reason.
The `ply_exporter_ply_data_test.SuzanneLoadPLYDataUV` fixture seems to be
unreliable and fails at random, even before this change. This makes it
hard to reliably get green light on all tests.
Pull Request #105504
Don't call recursion where it's redundant. The recursive algorithm
can carry dangerous behavior due to stack growth and overflow. The
probability is low for something like the frame nodes. But using a loop
is cheap, providing O(N = const) memory cost. A loop through the links
in a singly linked list is sufficient. The use of 2D vectors for
location mapping and other things can be separate.
Pull Request #105394
3e5ce23c99 introduced a regression in case the freed Main was part of a
list, and was supposed to be removed from it, since calling
`BLI_remlink` does _not_ clear the `prev`/`next` pointers of the removed
link.
This commit also contains a few more tweaks to recent related b3f42d8e98
commit.
Pull Request #105485
While this behavior can be useful in some cases, it can also create
issues (as in one of own recent commits, 3e5ce23c99), since it
implicetly keeps the removed linknode 'linked' to the listbase.
At least warn about it in the documentation of `BLI_remlink`.
This commit introduces a new Main boolean flag that marks is as invalid.
Higher-level file reading code does checks on this flag to abort reading
process if needed.
This is an implementation of the #105083 design task.
Given the extense of the change, I do not think this should be
considered for 3.5 and previous LTS releases.
Drivers: Introduce the Context Properties
The goal: allow accessing context dependent data, such as active scene camera
without linking to a specific scene data-block. This is useful in cases when,
for example, geometry node setup needs to be aware of the camera position.
A possible work-around without changes like this is to have some scene
evaluation hook which will update driver variables for the currently evaluating
scene. But this raises an issue of linking: it is undesirable that the asset
scene is linked to the shot file.
Surely, it is possible to have post-evaluation handler to clear the variables,
but it all starts to be quite messy. Not to mention possible threading
conflicts.
Another possibility of introducing a way to achieve the goal is to make it so
the dependency graph somehow parses the python expression where artists can
(and already are trying to) type something like:
depsgraph.scene.camera.matrix_world.col[3][0]
But this is not only tricky to implement properly and reliably, it hits two
limitations:
- Currently dependency graph can only easily resolve dependencies to a RNA
property.
- Some properties access which are valid in Python are not considered valid
RNA properties by the existing property resolution functions:
`camera.matrix_world[3][0]` is a valid RNA property, but
`camera.matrix_world.col[3][0]` is not.
Using driver variables allows to have visual feedback when the path resolution
fails, and there is no way to visualize errors in the python expression itself.
This change introduces the new variable type: Context Property. Using this
variable type makes allows to choose between Active Scene and Active View
Layer. These scene and view layer are resolved during the driver evaluation
time, based on the current dependency graph.
This allows to create a driver variable in the following configuration:
- Type: Context Property
- Context Property: Active Scene
- Path: camera.matrix_world[3][0]
The naming is a bit confusing. Tried my best to keep it clear keeping two
aspects in mind: using UI naming when possible, and follow the existing
naming.
A lot of the changes are related on making it so the required data is available
from the variable evaluation functions. It wasn't really clear what the data
would be, and the scope of the changes, so it is done together with the
functional changes.
It seems that there is some variable evaluation logic duplicated in the
`bpy_rna_driver.c`. This change does not change it. It is not really clear why
this separate code path with much more limited scope of supported target types
is even needed.
There is also a possible change in the behavior of the dependency graph: it
is now using ID of the resolved path when building driver variables. It used
to use the variable ID. In common cases they match, but when going into nested
data-blocks it is actually correct to use relation to the resolved ID. Not sure
if there was some code to ensure that, which now can be resolved. Also not sure
whether it is still needed to ensure the ID specified in the driver target is
build as well. Intuitively it is not needed.
Pull Request #105132
Currently, curves have a default offset of 1.0, while the initial (and
expected) value is 0.0. When resetting this value to its default, the
curve is now modified unexpectedly. This is most noticeable with text
objects: when resetting the offset of a new text, it will look very
broken.
Internally the value is stored with an offset of 1.0, with custom
setter and getter adding and subtracting 1.0 respectively. To give
this property a default of 0.0, we also need to add 1.0 to the initial
value upon curve creation.
Pull Request #105182
In order to properly translate UI messages, they sometimes need to be
disambiguated using translation contexts. Until now, node sockets had
no way to specify contexts and collisions occurred.
This commit adds a way to declare contexts for each socket using:
`.translation_context()`
If no context is specified, the default null context is used.
Pull Request #105195
This has the effect that the message is cut off at the end of the
first line. I copied the solution from other similar docstrings
elsewhere in the code.
As far as my regex-fu can tell, there are no other occurrences of this
in the codebase.
Issue reported by Joan Pujolar in #43295.
Pull Request #105474
**What are push constants?**
Push constants is a way to quickly provide a small amount of uniform data to shaders.
It should be much quicker than UBOs but a huge limitation is the size of data - spec
requires 128 bytes to be available for a push constant range.
**What are the challenges with push constants?**
The challenge with push constants is that the limited available size. According to
the Vulkan spec each platform should at least have 128 bytes reserved for push
constants. Current Mesa/AMD drivers supports 256 bytes, but Mesa/Intel is only 128
bytes.
**What is our solution?**
Some shaders of Blender uses more than these boundaries. When more data is needed
push constants will not be used, but the shader will be patched to use an uniform
buffer instead. This mechanism will be part of the Vulkan backend and shader
developers should not see any difference on API level.
**Known limitations**
Current state of the vulkan backend does not track resources that are in the
command queue. This patch includes some test cases that identified this issue as
well. See #104771.
Pull Request #104880
The up_axis_update/forward_axis_update was the same logic between
the two, so factor that out.
Also use the same time reporting logic in PLY as in OBJ/USD/Alembic.
When render is triggered from python and the render result is displayed
it isn't being updated as it wasn't tagged as being invalid.
Pull Request #105480
If the texture image path in the MTL is a "quoted" absolute path, the importer will fail to find the
file. It was only attempting to un-quote the path for the relative case. Now we attempt to un-quote
in all cases.
Pull Request #105478
If the texture image path in the MTL is a "quoted" absolute path, the importer will fail to find the
file. It was only attempting to un-quote the path for the relative case. Now we attempt to un-quote
in all cases.
Pull Request #105478
- Add missing braces for if statements
- Tweak variable naming to use snake case
- Use more common name for `MLoop`s of a face
- Use `std::move` when appending an array
- Use const for a few variable declarations
This commit implements three OSL microfacet closures that are needed to support
MaterialX: dielectric_bsdf, conductor_bsdf and generalized_schlick_bsdf.
Internally these map to existing microfacet closures, only the Fresnel term is
different.
Currently, we use the closure type to encode the type of microfacet distribution
(GGX/Beckmann/Sharp/MultiGGX), the lobes we're interested in
(Reflection/Refraction/both) AND the Fresnel type (None or Principled v1).
This results in the mess of dozens of options that we currently have. Since
adding Principled v2 and the MaterialX OSL closures will involve adding more
Fresnel types, this clearly doesn't scale.
But, since the earlier Fresnel rework (D17101), the Fresnel type only matters
in one place now. This allows to significantly clean up the closure type
handling. To do this, MicrofacetBsdfs now separately store their Fresnel type,
and instead of a single MicrofacetExtra we have one struct per Fresnel type
(unless no extra data is needed).
Further, instead of having one _setup() function per combination, the Fresnel
setup is also split into separate functions. This decouples the implementation
of new Fresnel terms from most of the Microfacet logic, and makes it a very
simple and clean operation.
This commit replaces the current Glass approach, where Glass is a virtual closure
that gets replaced with a Glossy and a Refractive closure, with a combined
closure that handles Fresnel after sampling the microfacet. That way, the Fresnel
term is more accurate since it accounts for the microfacet normal, not the
shading normal.
Also updates the BSDF sampling to use a 3D sampler now, since we need two
dimensions to pick the microfacet normal and then a third dimension to pick
reflection/refraction. This can also be used to get rid of the LCG in the
Principled Hair BSDF, which means we can remove it altogether once MultiGGX is
gone.
Also, "sharp" is now supported as a microfacet distribution in OSL, and 2
is supported as the "refract" argument to microfacet() in order to get glass.
Address some issues discussed in PR #104404:
- Vertex color options changed to None/sRGB/Linear, default is sRGB
to match the existing Python addon.
- Change name to "Stanford PLY" from "PLY" in the menu item.
- Default "Export UVs" to on.
- After importing vertex colors, they are set as enabled for render.
New (experimental) Stanford PLY importer and exporter written in C++.
Handles: vertices, faces, edges, vertex colors, normals, UVs. Both
binary and ASCII formats are supported.
Usually 10-20x faster than the existing Python based PLY
importer/exporter.
Additional notes compared to the previous Python addon:
- Importing point clouds with vertex colors now works
- Importing PLY files with non standard line endings
- Exporting multiple objects (previous exporter didn't take the vertex
indices into account)
- The importer has the option to merge vertices
- The exporter supports exporting loose edges and vertices along with
UV map data
This is squashed commit of PR #104404
Reviewed By: Hans Goudey, Aras Pranckevicius
Co-authored-by: Arjan van Diest
Co-authored-by: Lilith Houtjes
Co-authored-by: Bas Hendriks
Co-authored-by: Thomas Feijen
Co-authored-by: Yoran Huzen
msgfmt has a TBB dependency though bf_blenlib, now for a release build
The MSVC linker is smart enough to realize none of the TBB code is
actually used and discards it. In debug mode the linker is a bit more
conservative and doesn't, leaving msgfmt with a runtime dependency
on TBB. The problem here is, we only copy the runtime dlls during
the install phase, and msgfmt runs long long before that.
For this reason when we run msgfmt we should make sure any runtime
needs it could have are met in the path, there already is a handy
variable for that since oslc has similar requirements.
Pull Request #105048
During install all dlls should copy to the blender.shared
folder regardless if the dependency is on or off, creators
CmakeLists.txt already did this correctly, but for boost
the BOOST_POSTFIX and BOOST_DEBUG_POSTFIX variables were
not set causing the boost dll's not to be copied.
This change takes the setting of these variables out of the
WITH_BOOST block, but still guards it with a
WITH_WINDOWS_FIND_MODULES block so we don't break the build
for people building with that on.
When drawing text with multiple lines inside a frame node, depending
on the zoom level some lines would wrongly get clipped despite being
inside the clipping region.
This was caused by the clipping check in `blf_glyph_draw` not accounting
for the font’s aspect.
Pull Request #105389
Caused by b4100ed377. Image strips with only 1 frame of content do
expect any timeline frame to be translated into frame index of 0.
Check this case and return 0 explicitly.
Fix error in b4100ed377
`seq_retiming_evaluate()` returns range from 0 to 1, to which framerate
correction was applied. this is incorrect, and correction should be
applied to function input.
Unify both functions in one, with a more telling name,
to be sure of the order of the arguments. Some functional
cleanup of the using code to make it more explicit.
Pull Request #105413
When movie framerate does not match scene, content length was clamped to strip
length in scen framerate. This also caused issues with retiming which behaved in
similar way. Retiming was modified to use frame index of strip content, so even
when scene framerate is changed, retiming data is preserved in correct
proportions. This means, that handles are mapped to time in seconds rather than
to frames.
During the discussion for #101413 there was consensus that we could make
OIIO a mandatory dependency. This patch does just that.
The `idiff` testing tool remains optional.
Pull Request #105111
Similar to the previous commit, this simplifies future refactoring
to change the way edges are stored, and further differentiates
single poly variables from array pointers.
The issue was that when using the `HD_ALIGNED` handle type,
Blender would not automatically move the keyframe handles with the key.
Instead one handle would get stuck in place.
To remedy that manually move the keyframe handles in case the type is `HD_ALIGNED`
This makes it consistent with moving a key with G
Pull Request #105401
Consistently use edge draw flag instead of original index to determine if an
edge should be drawn or not.
In GPU subdivision the edge original index was used for both edge optimal
display and selection mapping to coarse edges, but they are not the same.
Now match the CPU subdivision logic and use a separate edge draw flag VBO.
For cage display, match Blender 3.3 behavior more in showing/hiding of edges
in wireframe mode. That is edges without a mapping to an original edge are
always hidden when there is no distinct cage, and drawn otherwise. This is
not ideal for e.g. the bevel modifier where it will always show some edges on
corners despite all edges being hidden by the user. But we currently have
no good information to decide if these should be hidden or not, so err on
the side of showing too much as it did before.
Fie #103706: bevel modifier edges not drawn correctly
Fix#103700: optimal display can't be turned of with GPU subdivision
Fix wrong edge display with GPU subdivision preceded by other modifiers
Pull Request #105384
Timer management code often loops over the list of timers, calling
independant callbacks that end up freeing other timers in the list. That
would result in potentail access-after-free errors, as reported in #105160.
The typical identified scenario is wmTimer calling wmJob code, which
calls some of the job's callbacks (`update` or `end` e.g.), which call
`WM_report`, which removes and add another timer.
To address this issue on a general level, the deletion of timers is now
deferred, with the public API `WM_event_remove_timer` only marking the
timer for deletion, and the private new function
`wm_window_delete_removed_timers` effectively removing and deleting all
marked timers.
This implements design task #105369.
Pull Request #105380
Window activation events on Windows-10 don't seem to be reliable as it's
possible for Alt-Tab to trigger WM_ACTIVATE on a window when switching
away from it. As detecting the keys which are held relies on a valid
active state - this meant Alt could become stuck when using Alt-Tab
to switch between windows.
Disable reading modifiers on activation for WIN32, activating the window
now clears modifiers on WIN32. This isn't ideal as held modifiers wont
be detected, re-introducing the error reported in #40059.
Previously, UBO bind locations were linearly incremented and
relied on the correct uniform location being queried. This fix
is a future requirement for EEVEE next, however, pulling forward
due to Issue #105280 highlighting a possible flaw with expected
uniform locations.
Authored by Apple: Michael Parkin-White
Ref #96261
Pull Request #105311
Intel GPUs exhibit a number of rendering artifacts.
The most substantial being incorrect resolve of reflections.
Splitting the reflections_resolve shader into two passes,
one for SSR and one for light probes ensures correct rendering
and optimal performance on this GPU.
Also resolves an artifact with ambient occlusion wherein
the pow(a, b) function causes excessive precision loss.
Using an alternative method for power calculation on these
platforms resolves the issues.
Authored by Apple: Michael Parkin-White
Ref T96261
Pull Request #105240
A bulk change, to make things moving as quickly as possible, instead of
doing per-modified-file basis.
This is pretty much direct translation of C code to C++, is not really
"proper" C++ usage. That could happen on a more case-by-cases basis.
Pull Request #105376
Metal backed requires HOST_READ texture usage flag
for irradiance grid. This was correctly in place for the
basic grid, but not for grid_prev.
Authored by Apple: Michael Parkin-White
Ref #96261
Pull Request #105312
Add overlay option for retopology, which hides the shaded mesh akin to Hidden Wire, and offsets the edit mesh overlay towards the view.
Related Task #70267
Pull Request #104599
Cleanup, try to always use const.
Many function signatures still have incorrect argument order
(constants, mutables). But this is a larger other cleanup.
Pull Request #104937
Increase the buffer sizes used for `BLI_str_format_uint64_grouped` to
prevent overflow on strings representing numbers within the uint64
range. Also creates and uses defines for all the formatted string
buffer sizes.
Pull Request #105263
This commit adds the ability to generate liboverrides of linked data at
the `BKE_blendfile_link_append` BKE level, and through the Python API
(the `BPY_library_load` context manager, aka `bpy.data.libraries.load`).
The python API was updated essentially to allow easy testing of the new
code. This commit also adds tests for the new 'override' behavior, and
for existing basic link one.
Current code only generates 'basic' overrides, without any handing of
hierarchies or dependencies, as for brush assets only the Brush ID needs
to be overridden.
That new feature does not aim at being exposed to user through the
link/append operations in its current state, as it is way too simplistic.
This change is a requirement for the Brush Asset project (#101908).
Pull Request #104746
The code of the 'Fix Deforms' operator was hard to read and inefficient, doing `O(num_vertices * num_vertex_groups)` evaluations of the mesh. It caused multiple issues and got in the way of improvements to Blender, and seems to be used very little (if ever).
It was decided in [last week's module meeting](https://devtalk.blender.org/t/2023-02-23-animation-rigging-meeting/27757#patch-review-decision-time-5) that this operator should be removed.
Pull Request #105237
Pick selection for the Curves object was not considering multi
object editing. Only the active object was considered.
This fix introduces pick selection for Curves for multi object editing.
Pull Request #105184
The toggle (for anything but float and int types) was swallowed in
bf948b2cef. Also seems ef68a37e5d discarded
`property_overridable_library_set` for bools.
Now treat the overridable toggle as a general property for all property
types.
Pull Request #105370
The map is used to, well, map localized copy of the tracks used by the
tracing thread to the original tracks in the movie clip. There seems to
be some accumulated stuff in there which is no longer used by the current
state of code.
There should be no functional changes.
Pull Request #105374
This PR removes the BKE_nlatrack_add, and adds new:
* BKE_nlatrack_insert_before
* BKE_nlatrack_insert_after
* BKE_nlatrack_new_before_and_set_active
* BKE_nlatrack_new_after_and_set_active
* BKE_nlatrack_new_head_and_set_active
* BKE_nlatrack_new_tail_and_set_active
methods to easily add new NLA tracks in relation to the existing track list.
Pull Request #104929
Under the following circumstances
* keys on 1, 3 and 5
* preview range set to 10-20
The frame channel operator would zoom into nothingness.
because no keys were found in the preview range.
(Only the `ANIM_OT_channel_view_pick` operator though)
This PR fixes it and notifies the user with a warning.
Pull Request #105179
Grease Pencil (when not in object mode) implements its own selection
opertor. This operator (`gpencil.select`) returns
`OPERATOR_PASS_THROUGH`, then falls though to `view3d.select` which can
toggle object selection (when using shift-click picking).
Removing `OPERATOR_PASS_THROUGH` would fix the object toggling, but this
was added in 62c73db734 with good reason (the tweak tool would not
work then).
Now prevent `view3d.select` from acting on Grease Pencil (when not in
object mode).
NOTE: longer term we could have grease pencil use view3d.select to avoid having to add these awkward exceptions
Pull Request #105342
Windows 11 has strange behavior with Alt-Tab.
In some cases an Alt-Press event is sent to the window immediately
after it is de-activated (both Left & Right Alt keys for some reason
even when only one is held).
This meant that:
- Modifiers could be enabled for de-activated windows
(so we can't assume de-activated windows have modifiers released).
- Releasing the modifier key would not be sent to the inactive window
causing the modifier key to be stuck.
- Button events over an inactive window are generated before activation,
so even though activation reads the correct modifier state,
the button event uses the "stuck" modifier state.
Now button & drop events on inactive windows always read the modifier
state first instead of relying on the modifier state to be cleared.
This has some advantages:
- If modifiers are held, they will be used as part of the click action.
- While modifier keys on inactive windows should be rare,
in the case this does happen - stuck keys are avoided.
So it makes sense to apply these changes for all platforms.
The current API makes more sense as part of a class, but for now, keep
consistency with the other geometry module headers and move the code
to the proper namespace, removing the `GEO_` prefix which is only meant
for C code.
Pull Request #105357
Also remove USE_WIN_ACTIVATE & USE_WIN_DEACTIVATE defines as they
were only added when changes to modifier handling failed on WIN32.
This logic has now been tested to work on all platforms.
These functions used internal values and only really make sense in
the context of the mesh validation process where they're used to remove
invalid elements from the mesh.
Note: Applies to both UV Sphere Projection and UV Cylinder Projection.
Adds a new boolean option "Preserve Seams" to UV Sphere Projection.
With "Preserve Seams" active, the Sphere projection will do a
greedy flood fill over the 3D topology, stopping at 3D boundaries
and also stopping at edges where "Mark Seam" has been used in the
3D Viewport.
During the flood fill, each face is mapped using the spherical
projection and then adjusted along the U axis so the UV map is
continuous across the shared edge.
With careful seam placement, this allows for the creation of a
spiral-cut-orange-peel unwrap, where a sphere can be unwrapped
into a single long continuous strip, wrapping multiple times around
the object.
Finally, if the flood fill process creates multiple UV Islands,
they are spaced along the `U` axis to prevent overlaps.
Pull Request #104847
With the goal of clearly differentiating between arrays and single
elements, improving consistency across Blender, and using wording
that's easier to read and say, change variable names for Mesh edges
and polygons/faces.
Common renames are the following, with some extra prefixes, etc.
- `mpoly` -> `polys`
- `mpoly`/`mp`/`p` -> `poly`
- `medge` -> `edges`
- `med`/`ed`/`e` -> `edge`
`MLoop` variables aren't affected because they will be replaced
when they're split up into to arrays in #104424.
This offers overflow checking in debug builds, avoids implicit
conversion to pointers, slicing features for future convenience,
and clarifies ownership. Also switch naming to plural like most
other arrays for further clarification.
This check is no longer needed as Campbell has removed the need to
pass around the active window. This check could potential be error-
hiding so best removed if not needed.
Pull Request #105351
This pull request adds a new tipe of resource handles (thin handles).
These are intended for cases where a resource buffer with more than one
entry for each object is needed (for example, one entry per material
slot).
While it's already possible to have multiple regular handles for the
same object, they have a non-trivial overhead in terms of uploaded
data (matrix, bounds, object info) and computation (visibility
culling).
Thin handles store an indirection buffer pointing to their "parent"
regular handle, therefore multiple thin handles can share the same
per-object data and visibility culling computation.
Thin handles can only be used in their own Pass type (PassMainThin),
so passes that don't need them don't have to pay the overhead.
This pull request also includes the update of the Workbench Next
pre-pass to use PassMainThin, which is the main reason for the
implementation of this feature.
The main change from the previous PR is that the thin handles are now
stored directly in the main resource_id_buf, to avoid wasting an extra
bind slot.
Pull Request #105261
Add specific modal keyitem for `Vert/Edge Slide` and `TrackBall`.
So they don't need to reuse modal items from other operators.
Note that there is a workround to avoid repeated keys in the status bar.
In `gesture_box_apply`, check if `exec` function returns
`OPERATOR_CANCELLED` and return 0 to prevent any undo items from being
created.
Pull Request #105065
This file has been tested on linux, other platforms may need some
tweaks, and/or dedicated files.
This is used to suppress errors with builds integrating ASAN sanitazing
tools, regarding memleaks detected in some third party libraries.
To use it, define the envvar option like that:
`LSAN_OPTIONS=print_suppressions=false:suppressions=/path/to/blender/source/tools/config/analysis/lsan.supp`
This is especially usefull when running ctest.
NOTE: Will also update https://wiki.blender.org/wiki/Tools/Tests/Setup
and https://wiki.blender.org/wiki/Tools/Debugging/ASAN_Address_Sanitizer
accordingly.
Applied for the motion tracking data data structures.
There are two advantages of doing so:
- More explicit and platform independent way of indicating that
something is legacy and is not to be accessed outside of the
versioning code.
- Simplifies conversion to C++ where having deprecated fields
triggers warning in implicitly defined assign operator.
Pull Request #105340
3e5ce23c99 introduced a regression in case the freed Main was part of a
list, and was supposed to be removed from it, since calling
`BLI_remlink` does _not_ clear the `prev`/`next` pointers of the removed
link.
This commit also contains a few more tweaks to recent related b3f42d8e98
commit.
While this behavior can be useful in some cases, it can also create
issues (as in one of own recent commits, 3e5ce23c99), since it
implicetly keeps the removed linknode 'linked' to the listbase.
At least warn about it in the documentation of `BLI_remlink`.
The active window was used by the NLA and the Graph editor however
this is not always available and not necessarily the window that
contains the area being initialized. Potentially causing the graph and
NLA spaces to be initialized with the wrong scene.
Active window access caused various awkward fixes in the past
([0], [1], [2]) which worked around the active window not being set.
Use a lookup for the window instead of accessing the active window.
Note that passing the window is an option too however this is only
used for versioning older files and is not be needed in most cases.
[0]: 20788e1747
[1]: 42f6aada98
[2]: 480e467ac9
As part of #95966, move the `ME_SEAM` flag on mesh edges
to a generic boolean attribute, called `.uv_seam`. This is the
last bit of extra information stored in mesh edges. After this
is committed we can switch to a different type for them and
have a 1/3 improvement in memory consumption.
It is also now possible to see that a mesh has no UV seams in
constant time, and like other similar refactors, interacting with
only the UV seams can be done with less memory.
The attribute name starts with a `.` to signify that the attribute,
like face sets, isn't meant to be used in arbitrary procedural
situations (with geometry nodes for example). That gives us more
freedom to change things in the future.
Pull Request #104728
This commit introduces a new Main boolean flag that marks is as invalid.
Higher-level file reading code does checks on this flag to abort reading
process if needed.
This is an implementation of the #105083 design task.
Given the extense of the change, I do not think this should be
considered for 3.5 and previous LTS releases.
GPUBatch.draw supports basic drawing methods. Although all
supported GPU backends support range based and instance based drawing.
This patch adds 2 methods to GPUBatch to add support to range based and
instance based drawing.
my_batch.draw_range(my_shader, elem_start=10, elem_count=5)
Will draw my_batch using my_shader. From the attached index buffer
elements 10-14 will be drawn.
my_batch.draw_instance_range(my_shader, instance_start=0, instance_count=10)
will draw my_batch using my_shader 10 times. Inside the vertex
shader the current instance number is held by gl_InstanceID.
Pull Request #104457
1. Changes the subdivision function to not fill in time but add 0 to fix bug #104824
2. Fixes a bug in sanitization function noticed while fixing this bug.
Pull Request #105306
Add a hash for faster look-ups on collection->gobject,
This avoids a full list lookup for every object added via Python's
CollectionObject.link as well as linking via BKE_collection_object_add_*
functions.
While the speedup is non-linear, linking & unlinking 100k objects from
Python is about 50x faster. Although unlinking all objects in order
(a best-case for linked lists) is approximately the same speed.
Ref !104553.
Update the style of the Python Console banner to "INFO" instead of
"OUTPUT".
This change makes it easier to difference user generated output from the
initial banner text.
This also has an advantage that "Copy as Script" excludes the banner.
Ref !105188.
Rewrite the logic to depend less on local variables and prefer spans
and indices over points and pointer arithmetic. Also make use of the
IndexRange type for some basic logic, correct the mesh that the
sharp edge layer was chosen from, and reduce variable scope.
The material indices from the caps were only copied if the base mesh had
a material index attribute. Fix that by copying them manually if the cap
has the attribute.
Search list's region is having its size members (winx and winy) set
to values that are one pixel too small. This causes text to look bad
as they are slightly off their pixel alignment.
See #105308 for more details and an illustration of the issue.
Pull Request #105308
Nodes are sorted based on the selection. In some cases (even depending
on processor speed, nodes can be selected and reordered, and another
operation can run before the next redraw). That gives a window where
operators mapped to the same input as selection can run with invalid
socket locations (which aren't updated after the nodes are reordered,
since they are stored in a separate array).
To fix this, move the socket locations from the node editor runtime
data to the node tree, tag them as invalid when the nodes are
reordered, and check for that status in a few more places.
A better longer term solution is not reordering nodes based on
UI status and instead storing the UI drawing order separately.
Pull Request #104420
Add check to WM_check for lack of wmWindowManager->winactive. Sets it
if there is a window and makes that one wmWindow->active as well.
Pull Request #105225
This patch fixes hanging unit tests when MetalRT is enabled. It simplifies and fixes the kernel selection logic by baking the MetalRT-specific options into `kernels_md5` rather than expanding out and testing MetalRT bit flags explicitly.
Pull Request #105270
This was backported from tmp-vulkan. When disabling the fence check
in ghost it is able to start blender. It will show a black screen
so not usable for users.
- make_update.external_script_add_origin_if_needed
returned None or an empty string. As neither where checked simply
return None.
- git_get_remote_url had an incorrect annotation.
Names such as `dummyult` and `dummyet` didn't read very well,
underscore separate these names.
Also rename some variables that used old conventions which missed
being updated (`mpr` for manipulator instead of `gz` for gizmo).
When an RNA type was registered, any existing dynamic types with the
same name were unregistered. This didn't account for built-in types
which cannot be unregistered in (most cases) allowing duplicate
operators for e.g. to be registered with the same name as existing
built-in operators (asserting with debug builds with GHash duplicates).
In practice the newly registered operator would be called unless
adding operators caused the GHash to be resized which could cause the
original operator to be used.
As registered RNA type identifiers are meant to be unique, don't allow
duplicate names in the first place. Now all dynamically registerable
RNA types prevent this situation, raising an error when scripts
attempt to register a type with an identifier matching the name of a
type that could not be removed.
Shortened in [0], increase to 1024 with the following changes:
- Use BKE_ST_MAXNAME for translation_context.
- Use OP_MAX_TYPENAME for wmOperatorType.name.
Both these limits were already used elsewhere but happened to use
RNA_DYN_DESCR_MAX (incorrectly).
[0]: f403d9a2b1
Consistent with naming from 1af62cb3bf. Keep the "coord"
naming in the "vert_coords_alloc" set of functions since they should be
removed (see #103789).
Caused by 96abaae9ac. Just keep the old argument
in the `_ex` version of the function for now. It can be removed
when the explode modifier is removed in 4.0.
Previously [D16255](https://developer.blender.org/D16255)
There is no option to adjust the edge_width like there is in the preferences for vertex_size and face_dot_size.
I only added the option for 3DView and UV/Image Editor, and limited both to a max size of 5 pixel, since the edges do not look very nice with too high values.
In the UV Editor only, there are always black outlines on the edges, I could not find a way to reduce the increasing thickness of these black outlines.
The default edge_width of 1 pixel:
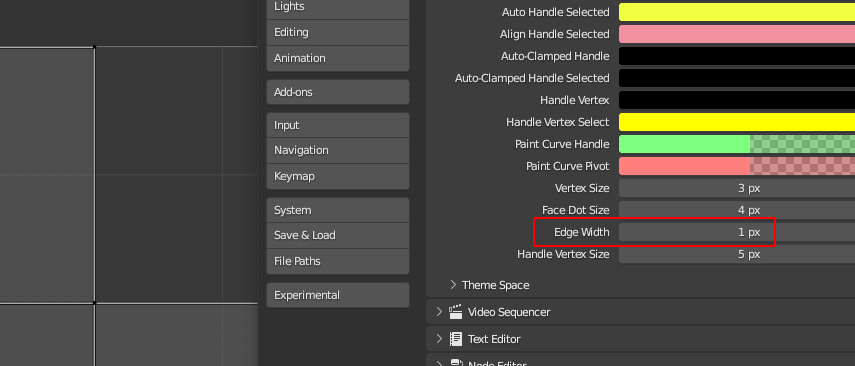
Here the edge_width with a falue of 3:
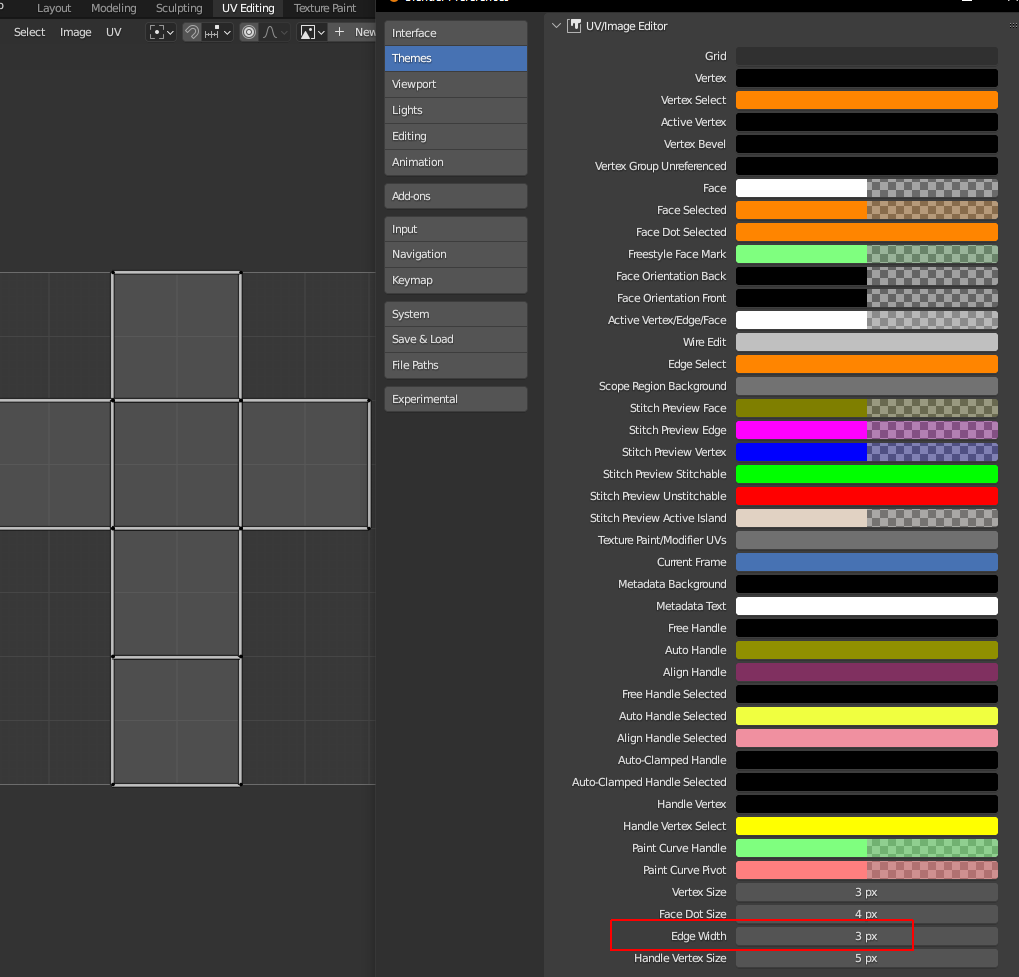
And here the visible increase of the dark border of the edges and their overlap (even at the maxed size of 5):
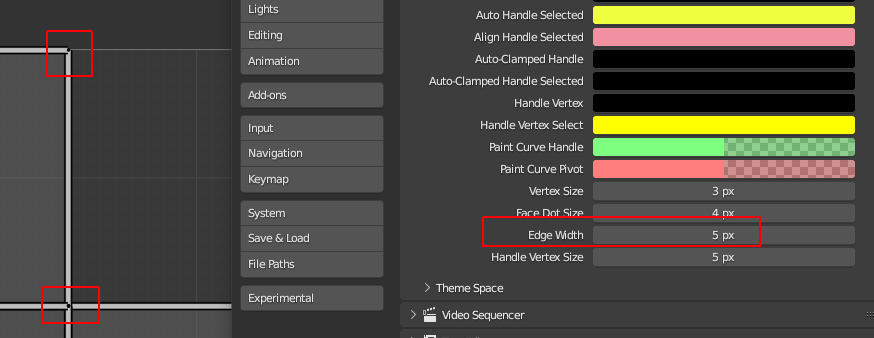
Lastly for the 3DView the max edge_width of 5 looks like this:
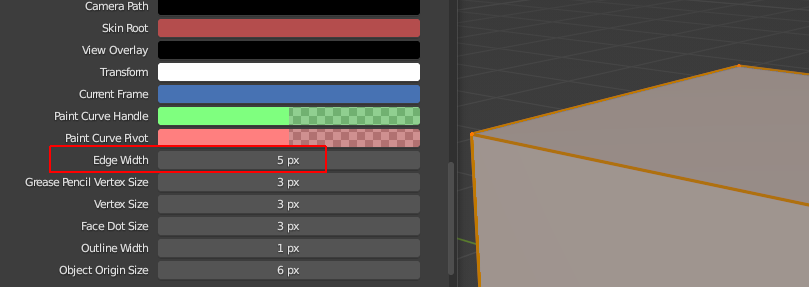
Pull Request #104741
When there are no loose edges, the loose edge bitmap shouldn't be used.
That was already documented in the loose edge storage struct, but the
bit vector wasn't actually cleared.
Share the bounds cache across the input and output meshes of some
mesh operations that don't change the min and max positions: simple
subdivision, edge/face deletion, and triangulation. If the source mesh's
bounds are computed, or if the mesh is persistent, this can save
recalculation of the bounding box, which takes a few milliseconds
for large meshes.
No behavior change intended.
Many file drag & drop handlers used the icon assigned for dragging to
determine what type of data is dragged. This is fragile, for example
changing an icon would break drag & drop (!). This happened a few times,
e.g. see 3788003cda. It's also causing problems with #104830, which
changes how file browser drag data is handled.
Instead use the file extension to determine the file type.
Exiting curves edit mode (going to object mode) would not update the
screen.
The fix adds a case to `ED_object_editmode_load_free_ex` for CURVES
to make sure the function returns properly. This then correctly adds the
notifier in `ED_object_editmode_exit_ex` to update the screen.
Pull Request #105252
- "Value" in the sense of color lightness is not the same word in
Japanese as other usages. See #105113.
- "Double" as a data type vs. a value.
Also extract "Custom Color Presets" in the tracking UI.
Run clang-format as well.
Pull Request #105187
This adds some simple null checks to avoid the crash. It might still
be good to improve the error message, but also does not seem as
important as avoiding the crash. Typically, users should not run into
this issue because the assets are shipped with Blender.
Actually is impossible to filter the Grease Pencil object type in the Outliner because only Meshes, Cameras and Lights are supported. This patch adds the Grease Pencil filter that allows artists to select only this type of objects. This filter is very handy for storyboarding.
Pull Request #104473
When using multiple compositor output nodes, compositing would fail
, showing a completely black output as it doesn't respect the active
node.
This patch will equalize the implementation with the viewer nodes.
Patch created by @OmarEmaraDevFixes: #86836
Pull Request #105235
Due to an error in GPU module we fixed the memory size in the
Vulkan backend. Last week the error has been fixed in the GPU module
so we can remove the temp fixes in the Vulkan backend.
Pull Request #105244
Similar to recent issues with gl_shader_interface,
ShaderInput lists need to be sorted to ensure correct
and efficient uniform lookup by name.
Authored by Apple: Michael Parkin-White
Ref #96261
Pull Request #105239
This commit adds the default .usdz export capability.
The importer already supports usdz so no change is required other than updating the text in menu to match the updated exporter text.
On export, a .usd/a/c file has to be created first, and then converted to .usdz. A weird change of directory is required because of a quirk with the USD conversion to usdz. If an absolute filepath is passed into the `UsdUtilsCreateNewUsdzPackage` function, the usd files inside the usdz archive will have the same directory structure, i.e. if one tries to create a file at `C:\code\BlenderProjects\file.usdz`, when the usdz file is created, inside it will have the structure `\code\BlenderProjects\file.usdc`.
This is counteracted by setting the current working directory to the temporary session directory where both the usdc and usdz files are created, and just passing the file name to `UsdUtilsCreateNewUsdzPackage` without any filepath. Once the usdz file is created it is moved to the intended directory.
There is a separate `UsdUtilsCreateNewARKitUsdzPackage` capability for exporting usdz for iOS devices that will be implemented in a follow up patch as it will require some more small UI changes.
Co-authored-by: Charles Wardlaw (@CharlesWardlaw)
Co-authored-by: Sonny Campbell (@SonnyCampbell_Unity)
Co-authored-by: Bastien Montagne (@mont29)
Pull Request #105185, based on #104556.
Pull Request #105223
While some implementations of `getcwd` may return an allocated string
instead of the given char buffer in some cases, this is not the expected
behavior of the BLI wrapper. Not to mention the danger of returning a
pointer to a static char buffer...
Improve `ChangeWorkingDirectoryTest` to be more 'full check' regarding
behavior of both `BLI_current_working_dir` and `BLI_change_working_dir`.
Also move call to `BLI_threadapi_init` into proper `SetUp` method (to
have correct symmetry with the call to `BLI_threadapi_exit` in the
`TearDown` one).
Based on investigation by Charles Wardlaw (@CharlesWardlaw).
Pull Request #105220
Add `BLI_change_working_dir(path)` to change the current working directory.
This change is required for adding USDZ support to Blender. When exporting to that format, we are required to do a weird change of directory because of a quirk with the USD library's USDZ functionality. If an absolute filepath is passed into the `UsdUtilsCreateNewUsdzPackage` function, the USDZ archive will store that full path.
macOS uses `NSFileManager` through some new Mac-only wrapper functions.
Ref #99807
Pull Request #104525
Apparently `git checkout -t` is only allowed to happen for new branches.
Added a code which checks whether the branch already exists and it so
uses the `git checkout <branch>`.
Pull Request #105234
* Refactored the color filter op to have an ->exec callback.
* Added nullptr checks to the filter cache API to support
running outside of a view3d context.
* Redo panel displays the active filter type's name in the
header.
To improve mesh upload speeds and reduce the size of the scene data which allows larger scenes to be rendered.
The meshes in Cycles are currently stored as flattened meshes, where each triangle is stored as a set of 3 vertices. Unflattening writes out the vertices in a list according to the index buffer. This uses a lot of memory and for current hardware does not provide a noticeable benefit. This change unflattens the mesh by directly using the meshes vertex and index buffers directly and skips the unflattening. This change allows for larger scenes and also a reduction in the sizes of the meshes. Further it results in a decrease the amount of time it takes to upload the data to a GPU. This is especially important for when multiple GPUs are used in a single machine.
Pull Request #105173
In Edges and Edges & Faces modes, the node copied the positions once
with the other generic attributes and another time specifically just as
the positions. This is now unnecessary since positions are stored as
a generic attribute (1af62cb3bf). In a simple test this saved
2ms out of a total 12 in these modes.
e8f4010611 unified the bounds computation for the new curves
object type and the rest of the curves system used by geometry nodes.
In the process, it made bounds affected by the control point radius.
In theory that makes sense; the bounds are supposed to be the extents
of the visible geometry. But in practice the change wasn't expected,
for a few reasons:
- The radius has never affected the bounds for the legacy curve type
- The default radius of legacy curve objects is absurdly large at 1.0m
- Only the new curve object has visible radius, and only in "strip"
mode or when rendering with Cycles
Currently the bounds are only used for the "Bounding Box" geometry node
and the panel in the 3D viewport sidebar, so there isn't any incentive
to choose less intuitive behavior yet.
Long term, the correct behavior is probably to include the radius in
the bounds, but this commit postpones that change to when it works
better with the rest of the curves system.
Pull Request #105154
Writing to a bitmap from multiple threads causes races when writing to
bits within the same integer. Instead, write to a separate boolean
array while subdividing, then move that to the final mesh bit vector.
Notes:
- The final copy to the bit vector could be replaced by a generic
`copy_from(Span<bool>)` call in the future.
- Theoretically we could entirely replace the `BitVector` with an
`Array<bool>`, but 1/8 the memory use for edges is likely worth it.
Pull Request #105156
The initial subdivision context counting ended up using unnecessarily
complicated logic to count the number of final vertices. In a first pass
it added vertices for every coarse edge. Then it added the same number
of vertices for every loose edge. That adds up to the same number of
vertices for the edges, so the separation is redundant and can be
replaced with a single multiplication.
The bitmap doesn't need to be cleared then, since it isn't used now.
In a test of a mesh with 2 million faces and 3 million vertices, this
saved 2.8ms (though the whole subdivision process takes around 700ms).
Pull Request #105159
This commit adds the default .usdz export capability.
The importer already supports usdz so no change is required other than updating the text in menu to match the updated exporter text.
On export, a .usd/a/c file has to be created first, and then converted to .usdz. A weird change of directory is required because of a quirk with the USD conversion to usdz. If an absolute filepath is passed into the `UsdUtilsCreateNewUsdzPackage` function, the usd files inside the usdz archive will have the same directory structure, i.e. if one tries to create a file at `C:\code\BlenderProjects\file.usdz`, when the usdz file is created, inside it will have the structure `\code\BlenderProjects\file.usdc`.
This is counteracted by setting the current working directory to the temporary session directory where both the usdc and usdz files are created, and just passing the file name to `UsdUtilsCreateNewUsdzPackage` without any filepath. Once the usdz file is created it is moved to the intended directory.
There is a separate `UsdUtilsCreateNewARKitUsdzPackage` capability for exporting usdz for iOS devices that will be implemented in a follow up patch as it will require some more small UI changes.
Co-authored-by: Charles Wardlaw (@CharlesWardlaw)
Co-authored-by: Sonny Campbell (@SonnyCampbell_Unity)
Co-authored-by: Bastien Montagne (@mont29)
Pull Request #105185, based on #104556.
While some implementations of `getcwd` may return an allocated string
instead of the given char buffer in some cases, this is not the expected
behavior of the BLI wrapper. Not to mention the danger of returning a
pointer to a static char buffer...
Improve `ChangeWorkingDirectoryTest` to be more 'full check' regarding
behavior of both `BLI_current_working_dir` and `BLI_change_working_dir`.
Also move call to `BLI_threadapi_init` into proper `SetUp` method (to
have correct symmetry with the call to `BLI_threadapi_exit` in the
`TearDown` one).
Based on investigation by Charles Wardlaw (@CharlesWardlaw).
Pull Request #105220
GPencil 3D stroke rendering uses a geometry shader.
This is unsupported by the Metal backend, so implement
fix for this failing compilation by shifting geometry shader
logic into the Vertex shader for Metal backend.
Authored by Apple: Michael Parkin-White
Ref #96261
Pull Request #105143
Metal LineLoop emulation path does not correctly apply
when using SSBO vertex fetch mode alongside 3D line
rendering.
Patch moves line emulation above SSBO
vertex fetch setup to ensure the correct emulation
parameters are passed to the shader.
Authored by Apple: Michael Parkin-White
Ref #96261
Pull Request #105142
Resolves issue with nearest filtering on UI Icons. Note that as
Metal does not support LOD bias as a parameter on a sampler
object, the original code has been modified to perform LOD
biasing at the shader level.
As GPU_SAMPLER_ICON is not widely used, it is more
efficient to apply directly to the affected shaders, rather
than workaround passing in the sampler LOD bias as a
separate value e.g. uniform or push constant.
Original PR feedback addressed to also refactor ICON
shaders to use consistent style for single and multi
Icon rendering.
Authored by Apple: Michael Parkin-White
Ref #96261
Pull Request #105145
This remove default casses from the `switch` statements to catch where
the missing cases are.
Uncomment unimplemented cases for the sake of completeness. Improving the
overall API.
This make the format conversion lists exhaustive and documented.
This replace `validate_data_format_mtl` by the common version as they
don't differ at all now.
After 7eda9d8dda, crash occurs when operation search is called and no
active tree element is present. Add missing null check in new poll
function to fix the crash.
Pull Request #105004
For every other texture types this is expected to be implicitly
`GPU_DATA_FLOAT`. There is only one case where this is not the case.
I believe this was previously needed because the data type was
conditionning the texture creation. This is not the case anymore.
Zero-sized gizmos were not shown because GPU does not draw filled
triangles with zero area. This problem is resolved by drawing lines or
points in these degenerated cases.
Scaling is supported via computing the original and the new size, then
treat the case with zero original size separately, instead of only
computing the scale itself.
Actually applies to all `cage2d` gizmos, but not compatible when
translate flag is set.
After 49ad91b5ab, an extra visibility
toggle is being drawn for grease pencil layer in dopesheet. In this PR,
a condition is added to skip drawing of visibility toggle for GPencil
layer. Also, Grease pencil does not support pinning so restore the offset
added to channel for drawing the pin icon.
Pull Request #105080
This is a workaround for [issue #104087](blender/blender#104087). We encounter crashes when using shader binary archives on AMD, so this disables them while we investigate a proper fix. Kernels will still be cached automatically by the OS file system cache. This cache may occasionally be purged due to external factors, in which case kernels will get compiled again.
Pull Request #105186
If repository has multiple remotes with the same name of branch
checking out to the branch using simple `git checkout branch` exists
with an error: this is because there is ambiguity w.r.t which remote
to track.
Now the code explicitly provides remote to track, preferring to use
"origin" first (which is to be used for Blender style of workflow,
and Github style workflow when there is a fork available), and use
"upstream" if there is no origin.
Pull Request #105176
The preset names were translated before building the UI. This meant
that the translated name was passed to the operator responsible for
deleting the preset file, instead of the original name.
Pull Request #105155
The preset names were translated before building the UI. This meant
that the translated name was passed to the operator responsible for
deleting the preset file, instead of the original name.
Pull Request #105155
This was actually caused by two problems. The first is that the
code actually deliberately detects if nothing happened and pushed
an undo step, a bugfix for a problem that no longer exists.
The second was that SCULPT_test_location sometimes does a closest
point search instead of ray casting and didn't check the result
against the brush radius.
This might've been a merge error, the result of color mixing
was being overwritten by a simple copy of source to destination
inside of layerCopyValue_propcol.
Revert #104679. We are just too used to the old behavior, especially
the incorrect vertical clipping. Some uses rely on setting the min and
max of the clipping rect the same. Will have to revisit this later
to only correct for horizontal positioning for full hinting.
Pull Request #105157
Own Code.
In 6514bb05ea I misinterpreted the function's intended
behavior when there was already an existing active layer. The data from
the active layer is just meat to be copied, the function should always
add a new attribute.
Blender currently has 2 algorithms for merging vertices:
- `BKE_mesh_merge_verts`;
- `blender::geometry::create_merged_mesh`
`BKE_mesh_merge_verts` has a simplified algorithm to work with Array,
Mirror and Screw modifiers. It doesn't support merge results that would
create new faces. However it has shortcuts to be more efficient in
these modifiers.
`blender::geometry::create_merged_mesh` tries to predict all possible
outcomes. So it's a more complex. But it loses in performance to
`BKE_mesh_merge_verts` in some cases.
The performance comparison between these two depends on many factors.
`blender::geometry::create_merged_mesh` works with a context that has
only the affected geometry. Thus a smaller region of the mesh is read
for duplicate checking. Therefore, the smaller the affected geometry,
the more efficient the operation.
By my tests `blender::geometry::create_merged_mesh` beats
`BKE_mesh_merge_verts` when less than 20% of the geometry is affected
in worst case `MESH_MERGE_VERTS_DUMP_IF_EQUAL` or 17% in case of
`MESH_MERGE_VERTS_DUMP_IF_MAPPED` .
For cases where the entire geometry is affected, a 30% loss was noticed,
largely due to the creation of a context that represents the entire mesh.
Co-authored-by: Germano Cavalcante <germano.costa@ig.com.br>
Pull Request #105136
When using the frame channel operators from #104523
the framing would fail under the following circumstance.
* In the graph editor
* Using normalized view
* with a curve that has a y-extent of less than the focus threshold of 0.01
The issue was the the clamping code was
before the normalization multiplication.
Pull Request #105121
When using the "Frame Channel" operator in the Dope Sheet
the view would always go back to the top.
Fix it by copying the y bounds when in the Dope Sheet.
Pull Request #105123
Using spans instead of raw pointers helps to differentiate ararys from
pointers to single elements, gives bounds checking in debug builds, and
conveniently stores the number of elements in the same variable.
Also make variable naming consistent. For example, use `loops` instead
of `mloop`. The plural helps to clarify that the variable is an array.
I didn't change positions because there is a type mismatch between
C and C++ code that is ugly to manage. All remaining code can be
converted to C++, then that change will be simpler.
Pull Request #105138
This code seems to be left over from before edges, polys, and loops were
stored in CustomData. They are already copied by the CustomData copy
calls directly above, which already deal with every other layer.
Resolving builtin uniforms and uniform blocks when creating
shader interface. This maps builtin uniforms to uniforms
defined by the shader. Works the same as the OpenGL
builtin uniforms.
Pull Request #105128
When using ShaderCreateInfo with builtin uniform(blocks) there are
cases where the current implementation could not find an existing
block. The reason is that it uses name matching and name matching
requires that the shader inputs are sorted based on the name hash.
This change fixes this by first for the sorting of the shader
inputs before resolving the builtins.
Pull Request #105127
Cycles fallback display shader previously did not use viewport.
This would crash or cause the display not to show when using
GPU backends other than OpenGL, if another display shader
was unavailable.
Now use ShaderCreateInfo for Cycles fallback display.
Authored by Apple: Michael Parkin-White
Ref #96261
Pull Request #104987
This patch will give access to the physical device limits
of the device associated with the context. In vulkan each
device has different limits and the application is
responsible to match these limits as the vulkan driver
just ignores calls that don't match these limits.
Those limits are GPUBackend specific and therefore are not
added to GPU_capabilities.
Pull Request #105125
If the resolution attribute exists, it needs to be set to a non-zero
value for the newly added curves. While it might also make sense
to interpolate the value from neighbor curves, for now it's
simplest to just set it to the default value of 12.
Pull Request #105094
In curves edit mode, the "Move Texture Space" and "Scale Texture Space"
operators where shown in the "Curves > Transform" menu.
Since these are not implemented, the fix removes these operators
from the menu.
The code below has to handle the case when `sample_length` is greater
or equal to the total length already anyway, so we can just make that
a valid input. Currently, the snake hook brush for curves also makes
use of passing in larger sample lengths which current results in crashes
in debug builds.
When trying to rotate in curves edit mode using proportional editing
and connected only mode, Blender would crash.
This was because the `TransData` structs for disconnected elements
did not have the location field populated, resulting in a null pointer
access.
The fix skips these elements entirely using `TD_SKIP`.
This fixes issue [#105100](blender/blender#105100) where multi-pass renders can be incorrect due to kernels using stale specialisation constants (e.g. when rendering Pokedstudio).
This patch adds a new group of md5 hashes (`global_defines_md5`) to track whether the injected block of #defines is stale and regenerate the source string as appropriate. It also renames the existing group of md5 hashes from `source_md5` to `kernels_md5` to clarify that these refer to a specific kernel set rather than just the source (which might build an arbitrarily large number of kernel sets).
Pull Request #105103
The translation contexts module wasn't imported after c7611d61e8,
which caused an error and prevented some constraints' UI from being
displayed.
Pull Request #105095
Extend the `GRAPH_OT_paste` operator with an enum to define the value offset.
Options are:
| Option | Effect |
| ------------------- | ----------------------------------------------------------------------------- |
| No Offset | use the same key values as the copied keys |
| Cursor Value | align the leftmost key with the cursor value |
| Current Frame Value | Evaluate the curve under the cursor align the leftmost key with it |
| Right Key | Align the rightmost key with the first key that is to the right of the cursor |
| Left Key | Align the leftmost key with the first key that is to the left of the cursor |
Pull Request #104512
Before that patch, the slider operators for the Graph Editor are not easily accessible since they don't have a hotkey.
This adds the "d" hotkey for the already existing slider operator menu.
Using the popup menu means that your last used operator will always be under the cursor, so it's quick to access.
Pull Request #104530
This might've been a merge error, the result of color mixing
was being overwritten by a simple copy of source to destination
inside of layerCopyValue_propcol.
When implementing the operator to select linked vertices in weight paint mode, the new `AtomicDisjointSet` was used.
In order to keep the code consistent, and also prepare it to add things like Extending/Shrinking selection, the select linked faces logic was also updated.
It now also makes use of the `AtomicDisjointSet` by connecting all edges of each poly. In order to find connecting Faces you then have to check if edges of that poly share a connection.
Pull Request #104577
The stoke shader of grease pencil uses a geometry shader stage. Apple
devices don't support shaders with geometry shader stage. In the
OpenGL driver there was a pass-through implemented so it didn't fail.
When using the metal backend this needs to be solved more explicitly.
This change patches the grease pencil shader to support both the
backends supporting a geometry stage and those without.
Fixes#105059
Pull Request #105116
This was actually caused by two problems. The first is that the
code actually deliberately detects if nothing happened and pushed
an undo step, a bugfix for a problem that no longer exists.
The second was that SCULPT_test_location sometimes does a closest
point search instead of ray casting and didn't check the result
against the brush radius.
Complex EEVEE nodegraphs, particularly those combining
multiple principledBSDF shader nodes have a tendancy
to require a large number of simultaneous live registers
due to function call depth. In some instances, this
causes substantial performance drop and corruption if
the stack gets too large.
To mitigate this, splitting calls to closure_eval such
that only a single individual closure is evaluated in each
call reduces the number of live registers required. This
is preferred over using compound closure evaluation
functions which require a large amount of in-flight data.
Note that this is generally not more optimal, if the stack
does not spill, as there is an increased instruction count.
The specific trade-off depends on the exact architecture
in question. Hence, this is limited to AMD GPUs.
Authored by Apple: Michael Parkin-White
Ref #96261
Pull Request #104985
On the Windows platform, raise windows and give them focus as the mouse
hovers over them. This allows keyboard shortcuts for the area under the
mouse without having to click the window caption to make them active.
Pull Request #104681
66dda2b902 made an incorrect change to account for the special
case for NURBS. Instead, make the step that turns the lengths into
parameters more explicit, and pass the correct total length for each
curve, even in the cyclic case.
Pull Request #105079
This resulted in disappearing NURBS curves when joining them with other
curve types in some cases. The attribute has to be handles similarly to
the radius and resolution attributes rather than as simple generic data.
The attribute was retrieved when converting to Bezier curves when it
wasn't necessary. Instead copy it like a regular attribute if any of the
result curves are NURBS. Also fix a check for an empty span for the
attribute which was never false.
Invalid node trees (e.g. when nodes are linked in a cycle) can not be
evaluated and the viewer is not available in them. This commit just adds
some null checks to handle this case more gracefully.
Expose the color selector on each item in the list, so it's easier to see
at a glance the Bone Groups color theme and change it.
Also avoids having color widgets grayed out when not in Custom Colors mode.
Pull Request #105036
This is refering to drag & drop within Blender which is using the
drop-box system.
Previously Escape would cancel the dragging, but still pass on the event
to other event handlers, which could trigger other behavior. For example
cancelling dragging a file in a file browser dialog would also cancel
the file browser operation and close the window. Right-click didn't
cancel anything even though we usually use both Escape and right-click
as a way to cancel the operation.
Now both escape and right-click both cancel the dragging and the event
is not passed on further.
Pull Request: #104838
Do the domain check directly in the field input class to avoid the need
for another function to do it elsewhere. Also move one function to
be closer to a similar one, rename some functions, and avoid the need
for two intermediate span variables.
Erroneous cache warming case where the generated material is
identical to default material and cached shader is re-used,
resulting in case where the parent shader is identical to the
source.
Authored by Apple: Michael Parkin-White
Ref #96261
Originally caused by 6514bb05ea
More cases where the active/default color attributes were not set
correctly:
[1] Using the old Python vertex_colors API (vertex_colors.new)
[2] OBJ importer
[3] Collada importer
[4] Data Transfer layout (both standalone operator and "Generate Data
Layers" from the modifier)
Similar to 101d04f41f.
Brought over from https://archive.blender.org/developer/D16977, see
discussion there why some of the code for data transfer is not for the
genereal attribute API.
Pull Request #105020
Descriptor set locations are now determined in the
VKShaderInterface. Issues with the previous solution:
- Due to legacy code in GPU module the locations/bindings
must be the same. Using one for something else might
result in undesired lookups, incorrect resource
bindings.
- Images/Textures reuses the same namespace, that didn't
work as expected when looking up the resources via
its binding.
This refactoring is required for adding support for
push constants.
Pull Request #105073
This tools allows to change strip playback speed by manipulating
retiming handles. More handles can be added to single strip to create
variable playback speed.
This tool replaces Speed Factor property in time panel, with exception
of sound strips. Support for sound strips is still in review.
Pull Request #104523
Drawing code `paint_draw_smooth_cursor` would be called correctly, it
was just the color not being initialized.
This is usually done with `BKE_paint_init`, but in the case of curves
sculpting brushes this would create an additional (unnamed) brush which
should be avoided since the workspace toolsystem creates the "right"
brush anyways.
So this patch just does the minimal work to get the Stabilize Stroke
indicator line to draw (which is initializing the color).
Brought over from https://archive.blender.org/developer/D16793
(cherry picked from commit 612a4382c443bcd02e0bb5ffd1b1fdbb251f6e7b)
Pull Request #105021
Arrays for curve handle types were allocated even when there were no
Bezier curves. This saves 0.5ms of the total 0.9ms spent creating the
evaluated curve offsets, which happens every time the topology
of non-poly curves change.
Revert of commits that allowed non-temp Blender windows to be saved
and restored that spanned multiple monitors on the Windows platform.
This causes problems with temp windows (like Preferences & Render) that
cannot currently be fixed.
See 104956 for much more details.
This change is being redone after it was accidentally reverted.
Differential Revision: blender/blender#104956
Reviewed by Ray Molenkamp
msgfmt has a TBB dependency though bf_blenlib, now for a release build
The MSVC linker is smart enough to realize none of the TBB code is
actually used and discards it. In debug mode the linker is a bit more
conservative and doesn't, leaving msgfmt with a runtime dependency
on TBB. The problem here is, we only copy the runtime dlls during
the install phase, and msgfmt runs long long before that.
For this reason when we run msgfmt we should make sure any runtime
needs it could have are met in the path, there already is a handy
variable for that since oslc has similar requirements.
Pull Request #105048
Add mouse hover highlighting for items in UILists, in both list mode
and preview tile mode.
See 104677 for more details
Differential Revision: blender/blender#104677
Reviewed by Brecht Van Lommel
Write RNA properties backed by IDProperties with the `IDP_INT` type like
before ef68a37e5d. That keeps forward compatibility, because
earlier versions don't support the boolean type. At some point in a future
release we can remove the forward compatibility. 4.0 is a good time to
do that because forward compatibility will be broken in other ways.
This commit also adds support for reading integer arrays for boolean
property defaults, which was only half-way supported before.
Pull Request #104995
The light tree itself is disabled on the AMD GPUs due to a compiler issue.
There are couple of places where this was not fully checked:
- The `light_sample` function in the kernel.
- The light threshold during synchronization
The former one is solved as easy as just adding an ifdef block.
The latter one is solved by delaying the threshold assignment for
later on.
Pull Request #105022
This commit implements described in the #104573.
The goal is to fix the confusion of the submodule hashes change, which are not
ideal for any of the supported git-module configuration (they are either always
visible causing confusion, or silently staged and committed, also causing
confusion).
This commit replaces submodules with a checkout of addons and addons_contrib,
covered by the .gitignore, and locale and developer tools are moved to the
main repository.
This also changes the paths:
- /release/scripts are moved to the /scripts
- /source/tools are moved to the /tools
- /release/datafiles/locale is moved to /locale
This is done to avoid conflicts when using bisect, and also allow buildbot to
automatically "recover" wgen building older or newer branches/patches.
Running `make update` will initialize the local checkout to the changed
repository configuration.
Another aspect of the change is that the make update will support Github style
of remote organization (origin remote pointing to thy fork, upstream remote
pointing to the upstream blender/blender.git).
Pull Request #104755
This patch adds initial support for compute shaders to
the vulkan backend. As the development is oriented to the test-
cases we have the implementation is limited to what is used there.
It has been validated that with this patch that the following test
cases are running as expected
- `GPUVulkanTest.gpu_shader_compute_vbo`
- `GPUVulkanTest.gpu_shader_compute_ibo`
- `GPUVulkanTest.gpu_shader_compute_ssbo`
- `GPUVulkanTest.gpu_storage_buffer_create_update_read`
- `GPUVulkanTest.gpu_shader_compute_2d`
This patch includes:
- Allocating VkBuffer on device.
- Uploading data from CPU to VkBuffer.
- Binding VkBuffer as SSBO to a compute shader.
- Execute compute shader and altering VkBuffer.
- Download the VkBuffer to CPU ram.
- Validate that it worked.
- Use device only vertex buffer as SSBO
- Use device only index buffer as SSBO
- Use device only image buffers
GHOST API has been changed as the original design was created before
we even had support for compute shaders in blender. The function
`GHOST_getVulkanBackbuffer` has been separated to retrieve the command
buffer without a backbuffer (`GHOST_getVulkanCommandBuffer`). In order
to do correct command buffer processing we needed access to the queue
owned by GHOST. This is returned as part of the `GHOST_getVulkanHandles`
function.
Open topics (not considered part of this patch)
- Memory barriers & command buffer encoding
- Indirect compute dispatching
- Rest of the test cases
- Data conversions when requested data format is different than on device.
- GPUVulkanTest.gpu_shader_compute_1d is supported on AMD devices.
NVIDIA doesn't seem to support 1d textures.
Pull-request: #104518
Contributed by Yulia Kuznetcova at Apple.
NanoVDB is patched to give add address spaces required by Metal. We hope that
in the future Metal will support the generic address space.
For AMD and Intel this is currently not available since it causes a performance
regression also on scenes without volumes.
Pull Request #104837
Alternatively this could use `ASSET_LIBRARY_ALL` like
`add_node_search.cc`, but then it would need a different
method for skipping duplicate local assets.
Mandatory change for the Brush Assets project, from quick test does not
seem to break anything (more) in existing 'old' brushes...
Re. #101908.
Pull Request #105016
This adds support for cursor snapping for the new curves object.
It implements a function `transverts_from_curves_positions_create` (to separate the logic from the `Curves` object type). That function is then C wrapped by `ED_curves_transverts_create` and finally used in `ED_transverts_create_from_obedit`.
Pull Request #104967
Fixes the `-Winconsistent-missing-override` warning.
In theory the `virtual` is redundant in such case, but this is how
it is done in may other areas of USD code.
Pull Request #104977
Previously when markers were used, the newly introduced clamping code (#104516) would stop the last channel from being shown.
This patch fixes that by modifying the `v2d->tot.ymin` calculation.
This is a bit counterintuitive since the `v2d->tot` height is calculated in `action_draw.c`. But the advantage of doing it there is that it also works for the channels region.
Pull Request #104892
This does 2 things to address the ARM64 failures:
- Increases the threshold to be inline with what Cycles uses
- Disables the 2 problematic WebP variations (#105006 will track)
This adds saving and loading tests for our supported image formats.
**Saving - bf_imbuf_save.py**
There are 2 template images which are loaded anew for each file save
attempt. One is an 8-bit RGBA image and the other 32-bit. This is
required as many formats use a variety of factors to determine which of
`ibuf->rect` or `ibuf->rectfloat` to use for processing. The templates
are constructed to have alpha transparency as well as values > 1 (or
clamped to 1 for the case of the 8-bit template).
Test flow:
- Load in an appropriate template image
- Save it to the desired format with the desired set of options
- Compare against the reference image
Notes:
- 98 references are used totaling ~3.6MB
- 10-12 second test runtime
- Templates can be reconstructed with the create-templates.blend file
**Loading - bf_imbuf_load.py**
Test flow:
- Load in each of the reference images
- Save them back out as .exr
- Save additional metadata to a secondary file (alpha mode, colorspace etc)
- Compare the saved out .exr with another set of reference .exrs
- Compare the saved out file metadata with set of reference metadata
Notes:
- 98 exr references are used totaling ~10MB
- 10-12 second test runtime as well
A HTML report is not implemented. The diff output organization is very
similar to the other tests so it should be somewhat easy to do in the
future if we want.
The standard set of environment variables are implemented for both:
BLENDER_TEST_UPDATE, BLENDER_VERBOSE, and BLENDER_TEST_COLOR
Pull Request #104442
Added new function sculpt_mesh_filter_cancel in sculpt_filter_mesh.cc
for cancelling mesh filters. It currently is unused pending a
revamped modal map for mesh filter (see pull req 104718).
In the outliner, the icons for modifiers are tinted blue. This didn't
work for the geometry nodes modifier icon.
Defining the icon with the macro `DEF_ICON_MODIFIER` also
defines the appropriate theme color so it's now tinted blue
when drawn in the outliner like the other modifier icons.
Pull Request #104957
Add a per node type callback for creating node add search operations,
similar to the way link drag search is implemented (11be151d58).
Currently the searchable strings have to be separate items in the list.
In a separate step, we can look into adding invisible searchable text
to search items if that's still necessary.
Resolves#102118
Pull Request #104794
Add `BLI_change_working_dir(path)` to change the current working directory.
This change is required for adding USDZ support to Blender. When exporting to that format, we are required to do a weird change of directory because of a quirk with the USD library's USDZ functionality. If an absolute filepath is passed into the `UsdUtilsCreateNewUsdzPackage` function, the USDZ archive will store that full path.
macOS uses `NSFileManager` through some new Mac-only wrapper functions.
Ref #99807
Pull Request #104525
The check was triggering the 'this' pointer cannot be null in
well-defined C++ code
We do not check for this pointer in any other areas. If it is
needed due to possible opaque pointer cast to the check prior
to the cast.
Pull Request #104974
That way the `matrix_base` doesn't need to depend on the axis
simplifying the code.
This also fixes an issue in plane scaling gizmos with non-orthogonal
matrix.
After rBdb87e2a638f9, two contexts were missing:
- VirtualReality, to be used in an add-on
- Constraint, used in the constraints UI
The latter was actually used without being added, which caused errors.
It was reverted in rB31a640027982.
The operator's description used a format string like:
```
BLI_sprintfN(TIP_("%s %s vertex groups of the active object"),
action_str, target_str)
```
which is almost guaranteed to be impossible to properly localize to
some languages -- I know there are a couple of issues for French
already.
So instead of hoping formatting works, write all possible strings
explicitly, even if it looks stupidly verbose.
Simplify modifier sample mode didn't transfer UV parameters, now fixed.
(This is the corrected commit, previous one has multiple other commits merged.)
Pull Request #104964
This reverts commit 19222627c6.
Something went wrong here, seems like this commit merged the main branch
into the release branch, which should never be done.
Currently Metal is more stable then the OpenGL backend on apple
devices. Also the Metal backend supports more features then the
OpenGL backend. For example the viewport compositor and rendering
of production files.
This has been validated with users and studios.
This patch will default to the Metal backend when starting
Blender 3.5 for the first time or when loading factory startup. It
is still possible to switch to OpenGL via the user preferences.
It will not automatically select the Metal backend when there is
already user preferences available for Blender 3.5.
No design or functional changes. Just rename the layers for the last
two icons that were added so that they follow the naming pattern.
Also, update the layer order for another icon (was not alphabetic).
Pull Request #104954
This is a missing part of the Metal backend. Metal backend doesn't
support the bgl commands, but it was not possible to use the gpu
module to use scissor testing.
Without this change addon developers would not be able to migrate
their addons to support the Metal backend.
This patch adds:
- `gpu.state.scissor_set`
- `gpu.state.scissor_get`
- `gpu.state.scissor_test_set`
Fix#104911
Texture clamping is by default off, but for VDM textures this leads
to several artifacts.
- Clamping is done when the image is sampled and when the brush strenght
is applied.
- VDM textures have negative values that are lost due to clamping
when clamping during sampling.
This patch fixes this by changing the default clamping of newly
created textures to not clamp anymore.
Textures are mostly being used by sculpt brushes, where clamping is also
implemented on brush level.
Fix#104747
Revert of commits that allowed non-temp Blender windows to be saved
and restored that spanned multiple monitors on the Windows platform.
This causes problems with temp windows (like Preferences & Render) that
cannot currently be fixed.
See 104956 for much more detail
Differential Revision: blender/blender#104956
Reviewed by Ray Molenkamp
Regression in [0] which caused interacting with 2D gizmos not to
update 3D gizmos once the gizmo finished it's modal interaction.
This caused the cameras lens gizmo not to update when navigating using
the viewport navigation buttons.
Resolve by detecting this case and flagging other draw steps to be
updated.
[0]: fb27a9bb98
Caused by 25237d2625, when the new "template" mesh created
in the modifier started to use the proper default value for CD_ORIGINDEX
layers rather than just zero. Zero isn't correct because it refers to
the first element, not "no element". For that we need to remove the
original index mapping arrays completely. There is some gray area
about whether that is allowed too, but it's best here to just keep the
old behavior working for now.
Add the `CD_ORIGINDEX` layer to the columns potentially displayed
with the Blender debug value of 4001 from the debug menu. Also
separate the debug columns to separate functions.
In the first loop is safe to remove the current element.
The second loop can remove any element, potentially the next.
This triggers a read after freed.
Pull Request #104897
When the new UV to legacy format conversion happens, the mesh is in
the middle of being written and is an at best "complicated", at worst
invalid state. The attribute API looks at other domains and is a bit
less forgiving in that respect, and shouldn't really be used here. Use
the CustomData API instead. Also sort the layers the same way as
b642dc7bc7.
Note that the node group has its sockets names translated, while the
built-in nodes don't. So we need to use data_ for the built-in nodes
names, and the sockets of the created node groups.
Pull Request #104889
This reverts commit 68181c2560.
I merged 3.6 into 3.5 by mistake. Basically I had a PR against main,
then changed it in the last minute to be against 3.5 via the
web-interface unaware that I shouldn't do it without updating the
patch.
Original Pull Request: #104889
Note that the node group has its sockets names
translated, while the built-in nodes don't.
So we need to use data_ for the built-in nodes names,
and the sockets of the created node groups.
Pull Request #104889
When animating it is often useful to frame the Graph Editor/Dope Sheet to whatever frames are in a given channel.
This patch adds the option to frame on selected channels OR frame on whatever channel is under the cursor.
If a preview range is set it will only focus on keys in that range.
Supports FCurve and keyframe data
Frame to selected is called with
* Right click in the channel section -> Frame Selected Channels
* or in Channel → Frame Selected Channels
* or hitting . on the numpad
Frame to channel under cursor is done with
ALT + Middle Mouse Button
Co-authored-by: Christoph Lendenfeld <chris.lenden@gmail.com>
Pull Request #104523
Finding the documentation for nodes can be time consuming.
By adding the online manual to the right click context menu in the node
editor the user gets easier access to the documentation.
Can also be used by custom nodes add-ons by registering a manual-map.
Pull Request #104833
When updating a mesh, the GPU Subdivision code makes calls to
`GPU_indexbuf_bind_as_ssbo()`.
This may cause the current VAO index buffer to change due to calls from
`glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, ibo_id_)` in
`GPU_indexbuf_bind_as_ssbo()`.
The solution is to unbind the VAO (by calling `glBindVertexArray(0)`)
before creating the index buffer IBO.
Co-authored-by: Germano Cavalcante <grmncv@gmail.com>
Pull Request #104873
Apparently, the 65bit Intel architecture is presented differently
on Linux and Windows.
Allow both variants for the command line, so that semantically the
command line argument can be seen as a lower case platform.machine.
When updating a mesh, the GPU Subdivision code makes calls to
`GPU_indexbuf_bind_as_ssbo()`.
This may cause the current VAO index buffer to change due to calls from
`glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, ibo_id_)` in
`GPU_indexbuf_bind_as_ssbo()`.
The solution is to unbind the VAO (by calling `glBindVertexArray(0)`)
before creating the index buffer IBO.
Co-authored-by: Germano Cavalcante <grmncv@gmail.com>
Pull Request #104873
Possible values are x86_64 and arm64.
Allows to use make_update.py in a cross-compile environment, like
building x86_64 macOS Blender from Apple Silicon machine.
Pull Request #104863
In the Dope Sheet and the Timeline, it was possible to drag the view until the keyframes were completely out of view.
(Important to drag in the region with the keyframes, dragging in the channel box already did clamping)
This patch adds a clamping mechanism matching that of the channel box. That means the last channel will stick to the bottom of the view.
Co-authored-by: Christoph Lendenfeld <chris.lenden@gmail.com>
Pull Request #104516
Fix a crash when using the Euler Filter from the Graph Editor on baked curves.
The crash happened because baked curves have no bezt array.
Skipping any curves where that was missing fixes the issue.
Co-authored-by: Christoph Lendenfeld <chris.lenden@gmail.com>
Pull Request #104858
3.2 and 1.6 where used as rough equivalents to M_PI & M_PI_2, however
this raised questions about the significance of these values.
Running thousands of tests with generated euler inputs I wasn't able to
detect a difference so use M_PI & M_PI_2 instead.
Fix a crash when using the Euler Filter from the Graph Editor on baked curves.
The crash happened because baked curves have no bezt array.
Skipping any curves where that was missing fixes the issue.
Co-authored-by: Christoph Lendenfeld <chris.lenden@gmail.com>
Pull Request #104858
According to the report it is a regression since 3.2, but it is tricky
to pin-point which exact commit caused it.
The root of the issue is that under certain circumstances frame might
be read and processed twice, depending on the order in which panels and
the main area is drawn: the footage information panel skips cache, so
it it is drawn prior to the main area it leads to 2 frame reads. Opening
the Metadata panel triggers code path which forces frame to be put to
the cache, solving the double frame read.
Solution is simple: do not skip cache when acquiring image buffer for
the footage information: the same frame will be needed for the main
area as well.
Pull Request #104860
On a user level there are no expected changes, other than being able
to update submodules and libraries from a main repository at a detached
HEAD situation (which did not work before).
On the infrastructure level of things this moves us closer to ability
to use the main make_update.py for the buildbot update-code stage, and
to remove the update-code section from the pipeline_config.yaml.
The initial idea of switching make_update to the pipeline config did
not really work, causing duplicated work done on blender side and the
buildbot side. Additionally, it is not easy to switch make_update.py
to use pipeline_config.yaml because the YAML parser is not included
into default package of Python.
There will be few more steps of updates to this script before we can
actually clean-up the pipeline_config: the changes needs to be also
applied on the buildbot side to switch it to the actual make_update.
Switching buildbot to the official make_update.py allows to much more
easily apply the submodules change as per #104573.
Having a threshold well above PI would result in discontinuity in some
cases.
The discontinuity can be measured by generating euler values (both
random and interpolated rotations), then comparing the accumulated
difference.
Changing the threshold for wrapping rotations produces at least as good
or more compatible results.
This was reported as #17297 and fixed in [0], however the change was
only applied for the game-engine.
Ref !104856
[0]: ab44742cf3
This was broken even before 0649e63716 and was always expanding the
`Image`, not the movie clip (even if the source was set to
`CAM_BGIMG_SOURCE_MOVIE`)
Now the rule here seems to be to always expand unconditionally, so
remove checking the source and always expand image and movie clip.
Co-authored-by: Philipp Oeser <philipp@blender.org>
Pull Request #104815
* Repeat last operator now works for mesh filters.
* Added an iteration_count property to repeat the filter.
This is especially useful when compounded with the repeat
last operator tool.
* The mouse event history is stored for mesh filters
with more advanced user input (mostly Smooth and Relax
filters).
meson defaults to debug builds [0] unless you tell it differently, this
diff changes the options for
- epoxy
- fribidi
- harfbuzz
- wayland
- wayland_protocols
to be optimized, mesa was already optimized
[0] https://mesonbuild.com/Builtin-options.html#core-options
Pull Request #104802
Passing a `BitSpan` is generally better because then the caller is not
forced to allocate the bits with a `BitVector`. Also, the `BitSpan` can
be stored in the stack, which removes one pointer indirection compared
to accessing bits through a `BitVector &`.
This adds `BitSpan` and `MutableBitSpan`. They work essentially the same as
the normal `Span` and `MutableSpan`, but work on individual bits instead
(the smallest type `Span` can handle is one byte large).
This also splits up `BLI_bit_vector.hh` and introduces two new headers:
`BLI_bit_ref.hh` and `BLI_bit_span.hh`.
The goal here is to make working with dynamically sized bit masks more
convenient. I'm mainly working on this because I might want to use this
in #104629. It can also be used to cleanup function signatures that
currently take a reference to a `BitVector`. Like with `Span` vs. `Vector`,
it is better to pass a `BitSpan` to function than a `const BitVector &`.
Unit tests for the new code are included.
Pull Request #104671
Cycles uses the "split faces" mesh function to support sharp edges
and auto-smooth. However, 75ad8da1ea updated that
function to ignore the edges that are explicitly tagged as sharp and
only use the edge angle. Fix by taking the attribute into account too.
The custom data layer mappings from dfacaf4f40 were created
*before* the BMesh shape key layers were added, invalidating the BMesh
data offsets they stored. Fix by creating the mappings after all layers
have been created.
Clean up logic to make it more clear and formalize the way to choose
fixed node data type based on operation. This make possible to more
easily fix wrong node data type for color type and less than ops.
Pull Request #104617
Fix: The BKE_nlatrack_remove_and_free (#104752) unit test leaks a little memory. Cleaning up the rest of the track list to ensure everything is freed.
Co-authored-by: Nate Rupsis <nrupsis@gmail.com>
Pull Request #104839
This PR adds 2 new methods:
* BKE_nlatrack_remove
* BKE_nlatrack_remove_and_free
and modifies the existing `BKE_nlatrack_free` to remove the track list parameter.
This refactor splits out the removal / freeing into it's own methods, and provides a higher order method (BKE_nlatrack_remove_and_free) to conveniently call both.
Co-authored-by: Nate Rupsis <nrupsis@gmail.com>
Pull Request #104752
When appending assets it often isn't expected for the asset tags and
meta-data to be included. Add an option to the append operator to
disable appending the asset data, exposing existing internal options.
This adds the "Select More/Less" operators for Curves. Both operators use the `select_adjacent` function to (de)select adjacent points.
Pull Request #104626
Code to set the dragging data for a button was mostly duplicated, they
share it now. The followup commit also needs an easy way to reuse the
logic, which is possible now.
No longer use the existance of an image pointer inside the button, or
the the type of a button to decide if the entire button should be
draggable, or only its icon. This was rather sneaky, undocumented
behavior. Instead make this a proper option in the public UI API, and
enable it by default in specific cases to match the previous behavior.
This at least makes the behavior known and controllable in the API, and
not something that's just "secretly" done deep down in the button
handling code. I'd argue we should just use the entire button width by
default for dragging, but that would be a bigger change.
When the users click the "Mark as Asset" with the mouse hover the fake
user button, the button was not refreshed. In fact, the areas are not
listening to the "NC_ID NA_EDITED", which is the signal emitted after
an asset is marked/unmarked. Because of this, the areas aren't redrawn
(especially the ID buttons).
This little patch adds the event listening for the areas where this
problem is happening node editor and properties editor.
Pull Request #104694
After the removal of the "normal" attribute providers, we no longer
use the concept of read-only attributes. Removing this status simplifies
code, clarifies the design, and removes potentially buggy corner cases.
Pull Request #104795
The "normal" was added before fields existed because we needed a
way to expose the data to geometry nodes. It isn't really an attribute,
because it's read-only and it's derived rather than original data.
No features have relied on the "normal" attribute existing, except
for the corresponding column in the spreadsheet. However, the
column in the spreadsheet is also inconsistent, since it isn't an
attribute but looks just like the other columns. The normal is
always visible in the spreadsheet.
Pull Request #104795
* Fix#92539: Hard to read the breadcrumbs.
* Fix View Item active, hover, and text color (e.g. count numbers in the
Spreadsheet were almost unreadable).
* Fix mismatching node type colors with the default theme.
Blender Light is meant to be simply a brighter version of the default,
so screenshots and tutorials can be followed with both themes.
* Use the same outline color for widgets, so they match when aligned in a row.
* Make panels standout (not fully transparent), like in the default theme.
The active tools in `_defs_curves_sculpt` don't use names that are
exactly the same as the corresponding brush name with "builtin_brush."
at the beginning, instead they use more standard identifiers without
capitals or spaces.
The "brush_select" utility operator assumed the names matched though.
That can be fixed by manually mapping the brushes to the active tools.
Pull Request #104792
The keymap name in `WM_keymap_guess_from_context` didn't match the
name of the keymap in the Blender default keymap (`km_sculpt_curves`).
Fix by changing the utility function to match the keymap name.
Before right clicking on any tool in curves sculpt mode gave an assert,
now it shows a context menu.
Pull Request #104791
In BKE_screen_area_map_find_area_xy (find a ScrArea by 2D location),
ignore edges by using screen verts instead of totrct
Differential Revision: blender/blender#104680
Reviewed by Brecht Van Lommel
Lookup cache was not invalidated, to update attached effects position, a handle
of a input strip is touched.
To update attached effects, currently the code only does that when strip
position is changed. This is, because effect strip updating is done internally
in sequencer module code and ideally shouldn't be done at all. A TODO comment
with further explanation is added.
On the Windows platform allow Blender windows to be created that are
spread over multiple adjacent monitors.
---
On Windows we are quite feature-complete and stable for the creation and placement of multiple (non-temp) Blender windows. We correctly do so across multiple monitors no matter their arrangement, resolution, and scale.
However, there is another way that Blender could use multiple monitors - suggested by a core dev - which is to size a window so that it comprises multiple monitors. There are some advantages to this way of working because the one window remains constantly active and in focus. It also allows a single region (like a node editor) to be as large as possible.
But this way of working is not currently possible. That is because during window creation we constrain them to fit within the confines of the nearest single monitor. This has mostly been done for simplicity and safety. We don't want to restore a saved window to a position where it cannot be seen or used.
This patch addresses that. It allows windows to span multiple monitors, and does so safely by constraining the four corners of the window to be within the working area of any active monitor. This means it allows the creation of single windows as shown below in blue (left two), but does not allow the one in orange (right):
Note this has been previously (before gitea) reviewed and approved by Brecht.
Co-authored-by: Harley Acheson <harley.acheson@gmail.com>
Pull Request #104438
Avoid running out of attributes when multiple material slots use the same one.
Cleanup:
Removes the return value from drw_attributes_add_request since it shouldn't be modified afterward and it's never used.
Avoid making copies of DRW_AttributeRequest in drw_attributes_has_request.
Co-authored-by: Miguel Pozo <pragma37@gmail.com>
Pull Request #104709
Now that the UV map names are read from the evaluated mesh the names of
the anonymous layers would show up in the UV Map node and be accessible
via the python interface.
This changes the collection definition to skip anonymous layers.
Pull Request #104783
Instead of retrieving which attributes to transfer from the geometry set
which exists at a different abstraction level, get them from accessors
directly with a newer utility function. This removes boilerplate code
and makes the logic clearer for a future even more generic attribute
propagation API.
The evaluated positions cache can live longer than a specific
`CurvesGeometry`, but for only-poly curves, it pointed to the positions,
which are freed when the curves are. Instead, use the same pattern
as the evaluated offsets and don't store the positions span, just return
it when retrieving evaluated positions.
The evaluated positions cache can live longer than a specific
`CurvesGeometry`, but for only-poly curves, it pointed to the positions,
which are freed when the curves are. Instead, use the same pattern
as the evaluated offsets and don't store the positions span, just return
it when retrieving evaluated positions.
There are known bugs in HIP compiler that are causing random build failures
when making changes to the Cycles kernel. This is preventing developers from
efficiently making improvements to Cycles.
For now Cycles AMD GPU rendering is disabled in Blender 3.6 until a good
solution is found, so that ongoing work like Principled v2 is not blocked.
We hope this can be resolved later on in the 3.6 release cycle.
Ref #104786
This reverts 1116d821dc and part of 5bac672e1a.
The solution was made specifically for the 3.5 release, to avoid
breaking other cases. The previous commit addressed the problem properly
by letting the general menu code align labels where needed.
Usually in Blender, we try to align the labels of items within a menu,
if necessary by adding a blank icon for padding. This wasn't done for
menus generated from enum properties (RNA or custom property enums). Now
we do it whenever there is at least one item with an icon.
Since the menu doesn't automatically align the labels like other menus
and pulldowns in Blender, I manually made them align using the blank
icon. However the menu button would also include this blank icon now.
This is a specific fix for the 3.5 release. In the main branch I will
replace it with proper support for automatically aligning labels in such
menus.
Since the menu doesn't automatically align the labels like other menus
and pulldowns in Blender, I manually made them align using the blank
icon. However the menu button would also include this blank icon now.
This is a specific fix for the 3.5 release. In the main branch I will
replace it with proper support for automatically aligning labels in such
menus.
* BLENDER_VERSION_CYCLE set to beta
* Update pipeline_config.yaml to point to 3.5 branches and svn tags
* Update and uncomment BLENDER_VERSION in download.cmake
Usually when a menu item displays an icon, we indent all other items
with an empty icon so items align nicely. Now with more built-in asset
libraries (the new "Essentials" library), this inconsistency becomes
more apparent.
Also add a separator line between the "All" asset library and the
others, makes the menu look more organized.
The Preferences for asset libraries are becoming more than a simple name
+ path. E.g. there is now an Import Method options, and we previously
also considered a Relative Paths option (which we may still want to
add). The previous UI, while consistent with the Auto Run Python Scripts
UI isn't well suited for less than trivial cases. Using UI lists makes
the UI more scalable and follows usual list UI patterns more. There is
also more space for the path button now.
Part of #104686.
The default import method for an asset library can now be determined in
the Preferences. The Asset Browser has a new "Follow Preferences" option
for the importing. The essentials asset library still only uses "Append
(Reuse Data)".
This is part of #104686, which aims at improving the import method
selection, especially for the introduction of the new essentials library
(which doesn't support certain import methods). Further changes are
coming to improve the UI, see #104686.
Pull Request: #104688
The quick fur operator now uses the new hair system. It adds a new
curves object for every selected mesh, and adds geometry nodes
modifiers from the essentials assets that generate curves. A few
settings are exposed in the redo panel, including an option for whether
to apply the modifier to generate the initial curves so that there is
original editable data.
The point of the operator is to give people a sense of how to use the
node groups and to give a very fast way to build a basic setup for
further tweaking.
Pull Request #104764
Use the right hand side selection, as it fits the typical workflow
the best.
Arguably, the same would need to be done for the k-shortcut, but
that is another issue to be tackled. As well as making the selection
active.
Pull Request #104777
We (Dalai, Hans, Falk, Simon and me) decided that the curves edit mode
is useful enough to justify moving it out of experimental now. So far it
supports the following features:
* Various selection tools. The selections are synced with sculpt mode.
* Transform tools.
* Delete curves/points.
More functionality of the old curve edit mode will be ported over in
future releases.
This implements the delete operator in curves edit mode. The behavior
is similar to the delete operator in the edit mode of legacy curves,
i.e. it's actually dissolving and doesn't split curves. This is also
the behavior that we generally want for the hair use case.
The operator is added to the `Curves` menu and can be accessed via
the keyboard using `X` or `Del`.
Pull Request #104765
This adds a new `Curve Falloff` popover to the comb brush tool settings.
The curve control allows changing the brush weight along the curve to
e.g. affect the tip more than the root. This is a relative way to get
something like stiffness for short hair.
This functionality could potentially be added to some other brushes,
but the comb brush is the most important one, so that is added first.
I did add the buttons add the buttons to choose a curve map preset.
However, I did not add the preset dropdown, because that just adds
some unnecessary complexity in the code now and is redundant.
Pull Request #104589
This patch adds a simple operator to set values of the active
attribute for the selected element. The aim is to give simple control
over attribute values in edit mode rather than to provide the fastest
workflow for most cases. Eventually this operator might be less
important compared to more advanced attribute editing tools, but for
now, exposing a little bit of functionality is low hanging fruit and
will help to see the possibilities.
The implementation mostly consists of boilerplate to register the
necessary property types for the operator and draw their UI.
Beyond that, we just loop over selected elements and set a value.
Pull Request #104426
Caused by strips being flagged for removal, but the flag was never
cleared. As far as I can tell, this issue is not reproducible anymore,
but there may be files with this flag still set.
overlay_uniform_color_clipped was inheriting from overlay_depth_only, which doesn't
make much sense.
I've changed it to inherit from overlay_uniform_color instead, which is consistent
with other \*\_clipped variants of shaders.
Pull Request #104761
Certain material node graphs can be very expensive to run. This feature aims to produce secondary GPUPass shaders within a GPUMaterial which provide optimal runtime performance. Such optimizations include baking constant data into the shader source directly, allowing the compiler to propogate constants and perform aggressive optimization upfront.
As optimizations can result in reduction of shader editor and animation interactivity, optimized pass generation and compilation is deferred until all outstanding compilations have completed. Optimization is also delayed util a material has remained unmodified for a set period of time, to reduce excessive compilation. The original variant of the material shader is kept to maintain interactivity.
Also adding a new concept to gpu::Shader allowing assignment of a parent shader from which a shader can pull PSO descriptors and any required metadata for asynchronous shader cache warming. This enables fully asynchronous shader optimization, without runtime hitching, while also reducing runtime hitching for standard materials, by using PSO descriptors from default materials, ahead of rendering.
Further shader graph optimizations are likely also possible with this architecture. Certain scenes, such as Wanderer benefit significantly. Viewport performance for this scene is 2-3x faster on Apple-silicon based GPUs.
Authored by Apple: Michael Parkin-White
Ref T96261
Pull Request #104536
The logic for looping over imported OBJ faces and checking whether any
of them are "invalid" (duplicate vertices) was wrongly skipping
validation of the next face right after some invalid face. It
was the previously invalid face, moving the last into its place,
but then the loop was incrementing the face index and that just-moved
face was not properly validated.
Fixes#104593 - importing attached obj file (which contains some faces
that have duplicate indices). Added test coverage with a much smaller
obj file.
When the attribute doesn't exist, the node should give the default
of 12, as defined by the accessor method for `bke::CurvesGeometry`.
Pull Request #104674
This better aligns with OSX/Linux warnings.
Although `__pragma(warning(suppress:4100))` is not the same as
`__attribute__((__unused__))` in gcc (which only affects the attribute
instead of the line), it still seems to be better to use it than to
hide the warning entirely.
As described in #104171, add an operator that creates a new node group
that contain the current node group and named attribute nodes to deal
with the outputs. This saves manual work when moving a high-level
modifier to the node editor for better procedural control.
Pull Request #104546
This adds a new overlay for curves sculpt mode that displays the curves that the
user currently edits. Those may be different from the evaluated/original curves
when procedural deformations or child curves are used.
The overlay can clash with the evaluated curves when they are exactly on top of
each other. There is not much we can do about that currently. The user will have
to decide whether the overlay should be shown or not on a case-by-case basis.
Pull Request #104467
This renames `data` and `color` to `selection`. This is better because
it's actually what the corresponding buffers contain. Using this
more correct name makes sharing vertex buffers between different
gpu batches for different shaders easier.
The "current file" mode is only useful when creating new assets.
However, the far more common use case and the one that should require
fewer steps is to use existing assets.
There is a risk that this causes freezing if the file browser preview
caching does not work properly. So we'll have to keep an eye on the bug
tracker to see if this is an issue in practice.
Pull Request #104749
This patch adds an "Essentials" asset library that is bundled with Blender.
Also see #103620. At build time, the `lib/assets/publish` folder is copied
to `datafiles/assets` in the build directory.
In the UI, the "Essentials" library can be accessed like other custom asset
libraries with the exception that assets from that library cannot be linked.
The immediate impact of this is that Blender now comes with some geometry
node groups for procedural hair grooming.
Pull Request #104474
The OBJ spec (page B1-17) allows "l" entries to specify
polylines with more than 2 vertices, optionally with texture
coordinates.
Previously, only the first 2 vertices of each polyline
were read and added as loose edges, failing when texture
coordinates were present.
This adds support for proper polylines, reading but ignoring
texture coordinates.
Pull Request #104503
In 161908157d we moved all warnings
coming out of the library folder to /W0 as many of them do not follow
our code-style nor can we force them to.
When i made this change, i took `/external:templates-` to mean
"and that goes for you too, templates" and it decisively does the
opposite leading to /W3 warnings coming out of openvdb
This change removes the flag as it should have never have been added
in the first place.
Sculpt: Added vector displacement for the sculpting draw brush (area plane mapping only for now)
Vector displacement maps (VDM) provide a way to create complex displacements that can have overhangs in one brush dab.
This is unlike standard displacement with height maps that only displace in the normal direction.
Forms like ears, curled horns, etc can be created in one click if VMDs are used.
There is a checkbox on the draw brush in the texture settings "Vector Displacement" that enables/disables this feature.
Technical description: The RGB channels of a texture in a brush stroke are read and interpreted as individual vectors, that are used to offset vertices.
As of now, this is only working for the draw brush using the area plane mapping. Symmetry and radial symmetry are working.
A few things to consider when making VD-Maps:
* UVs need to stay intact for the bake mesh (e.g. voxel remeshing can't be used to create VD Meshes)
* When exporting a VD Map it should be in the file format OpenEXR (for positive and negative floating point values).
* Export resolution can be 512x512 or lower (EXR files can get very large, but VDM brushes don't need a high resolution)
And when using them:
* Inside Blender clamping needs to be unchecked on the texture
* The brush falloff should be set to constant (or nearly constant)
This patch was inspired by this [right-click-select proposal](https://blender.community/c/rightclickselect/WqWx/) Thanks for the post!
(Moved [this patch](https://archive.blender.org/developer/D17080) to here.)
Co-authored-by: Robin Hohnsbeen <robin@hohnsbeen.de>
Pull Request #104481
Curve type counts are updated eagerly but it was missing in this
node leading to a crash further down the line where the counts
were expected to be correct.
`MEM_delete()` is designed for type safe destruction and freeing, void
pointers make that impossible.
Was reviewing a patch that was trying to free a C-style custom data
pointer this way. Apparently MSVC compiles this just fine, other
compilers error out. Make sure this is a build error on all platforms
with a useful message.
The Volume property of the Maintain Volume constraint was marked as a
distance, which made it confusing--especially with non-metric units.
The volume can actually be understood as a factor of the initial
volume, so it should be dimensionless.
Additionally, the volume had a range of 0.001 to 100.0. This is wide
enough in most cases, but sometimes you may need to go orders of
magnitude higher or lower to consider vast or thin objects, and there
should be no drawback to extending the limits, provided they stay
positive.
Pull Request #104489
The proper fix (bb9eb262d4) caused compilation problems with HIP, so we're
delaying it until 3.6.
To fix the original bug report (#104586), this is a quick workaround that'll
hopefully not upset the compiler.
Pull Request #104723
A properly authored USD file will have the extent attribute authored on all prims conforming to UsdGeomBoundable.
This cached extent information is useful because it allows the 3D range of prims to be quickly understood without reading potentially large arrays of data. Note that because the shape of prims may change over time, extent attributes are always evaluated for a given timecode.
This patch introduces support for authoring extents on meshes and volumes during export to USD.
Because extents are common to multiple kinds of geometries, the main support for authoring extents has been placed in USDAbstractWriter, whose new author_extent method can operate on any prim conforming to pxr::UsdGeomBoundable. The USD library already provides us the code necessary to compute the bounds for a given prim, in pxr::UsdGeomBBoxCache::ComputeLocalBound.
Note that not all prims that are imageable are boundable, such as transforms and cameras.
For more details on extents, see https://graphics.pixar.com/usd/release/api/class_usd_geom_boundable.html#details.
Note that when new types of geometries are introduced, such as curves in https://developer.blender.org/D16545, we will need to update the USD writer for that geometry such that it calls this->author_extent.
Update on Feb 2: This patch has been updated to include a unit test to ensure authored extents are valid. This test requires new test assets that will need to be submitted via svn. The test assets are attached in the d16837_usd_test_assets.zip file. To use, unzip and merge the contents of this zip into the lib/tests/usd folder.
This unit test also addresses #104269 by validating compliance of exported USD via UsdUtils.ComplianceChecker.
Pull Request #104676
Use a MAKE wrapper for 'make deps' on Linux that ensures dependencies
are built one at a time. This is preferable because building many
dependencies at once made troubleshooting impractical and had the
downside that large deps such as LLVM would bottleneck on a single core.
This may be used for macOS, so far it's only tested on Linux.
- Correct broken link for undocumented modules.
Point to the contributing page, it seems #51062 was lost with the
GITEA task migration.
- Correct Blender Version link to the SHA1.
Matching the RNA id's to the search pattern is slow because
of the function `fnmatchcase`. This patch first checks the string
prefix without any special characters used by fnmatch,
if the `startswith` check fails, there is no need to check `fnmatchcase`.
Before the optimization, an online manual lookup took about 400ms
which is quite noticeable, with this patch applied it's under 10ms.
Ref !104581.
The internal compiler error appears to be gone. Unclear why it appeared in the
first place and why it's gone now. Just random kernel code changes causing it.
Pull Request #104719
- Rename roughness variables for more clarity - before, the SVM/OSL code would
set s and v to the linear roughness values, and the setup function would over-
write them with the distribution parameters. This actually caused a bug in the
albedo code, since it intended to use the linear roughness value, but ended up
getting the remapped value.
- Deduplicate the evaluation and sample functions. Most of their code is the
same, only the middle part is different.
- Changed albedo computation to return the sum of the intensities of the four
BSDF lobes. Previously, the code applied the inverse of the color->sigma
mapping from the paper - this returns the color specified in the node, but
for very dark hair (e.g. when using the Melanin controls) the result is
extremely low (e.g. 0.000001) despite the hair still reflecting a significant
amount of light (since the R lobe is independent of sigma). This causes issues
with the light component passes, so this change fixes#104586.
- There's quite a few computations at the start of the evaluation function that
are needed for sampling, evaluation and albedo computation, but only depend on
the view direction. Therefore, just precompute them - we still have space in
PrincipledHairExtra after all.
- Fix a tiny bug - the direction sampling code did not account for the R lobe
roughness modifier.
Pull Request #104669
In order to experiment with different storage types for `DRW_Attributes`
and for general cleanup (see #103343). Also move a curves header to C++.
Pull Request #104716
The existing logic to copy `BMesh` custom data layers to `Mesh`
attribute arrays was quite complicated, and incorrect in some cases
when the source and destinations didn't have the same layers.
The functions leave a lot to be desired in general, since they have
a lot of redundant complexity that ends up doing the same thing for
every element.
The problem in #104154 was that the "rest_position" attribute overwrote
the mesh positions since it has the same type and the positions weren't
copied. This same problem has shown up in boolean attribute conversion
in the past. Other changes fixed some specific cases but I think a
larger change is the only proper solution.
This patch adds preprocessing before looping over all elements to
find the basic information for copying the relevant layers, taking
layer names into account. The preprocessing makes the hot loops
simpler.
In a simple file with a 1 million vertex grid, I observed a 6%
improvement animation playback framerate in edit mode with a simple
geometry nodes modifier, from 5 to 5.3 FPS.
Fixes#104154, #104348
Pull Request #104421
Don't crash on nonexisting uv selection layers. Add an assert
because for now it is a bug if they don't exist. But when converting
back to Mesh it is preferable to accept in release mode, as opposed to
crashing.
Pull Request #104600
When generating a Mesh from a BMesh the uv map bool layers are not
copied if all elements are false. To suppress the copying the flag
CD_FLAG_NOCOPY is set in the layer flags. However these layers *do*
need to be copied to other BMeshes (for example undo steps). So we
need to clear them afterwards.
This commit adds the ability to import USD Shape primitives (Gprims).
They are imported as Blender Meshes using the USD API to convert, so
that they appear the same as they would in other applications. USD
Shapes are important in many workflows, particularly in gaming, where
they are used for stand-in geometry or for collision primitives.
Pull Request #104707
The issue was caused by rather recent refactor in 7dea18b3aa.
The root of the issue lies within the fact that the optical center was updated
on the Blender side after the solution was run. There was a mistake in the code
which double-corrected for the pixel aspect ratio.
Added a comment in the code about this, so that it does not look suspicious.
Pull Request #104711
`CTX_wm_operator_poll_msg_set()` is covered by the translation script
and always translates these strings. Checked with Bastien, he prefers
not having the redundancy here.
## Cleanup: Refactor NLATrack / NLAStrip Remove
This PR adds 3 new methods:
* BKE_nlatrack_remove_strip
* BKE_nlastrip_remove
* BKE_nlastrip_remove_and_free
These named BKE methods are really just replacements for BLI_remlink, but with some added checks, and enhanced readability.
Co-authored-by: Nate Rupsis <nrupsis@gmail.com>
Pull Request #104437
Send a notification and tag for an update even if the selection doesn't
exist, which is still necessary for drawing that depends on the
selection domain.
As a side effect of this change, more resolution divisions are now available.
Before this patch the possible resolution divisions were all powers of two.
Now the possible resolution divisions are the multiples of pixel_size.
This increase in possible resolution divisions is the same idea proposed in https://archive.blender.org/developer/D13590.
In that patch there were concerns that this will increase the time between a user navigating
and seeing the 1:1 render. To my knowledge this is a non-issue and there should be
little to no increase in time between those two events.
Pull Request #104450
This is needed to be able to query asset library information from an
asset. This again is relevant especially for the "All" asset library,
where you can't just directly access the library itself, which is
different for different assets.
The current design is that an asset representation is owned by exactly
one asset library, so having this pointer is perfectly compatible with
the design.
Reviewed by: Julian Eisel
This replaces `GPU_SHADER_3D_POINT_FIXED_SIZE_VARYING_COLOR` by
GPU_SHADER_2D_POINT_UNIFORM_SIZE_UNIFORM_COLOR_OUTLINE_AA`.
None of the usage made sense to not use the AA shader.
Scale the point size to account for the rounded shape.
Ref #104280
The scaling of area light / spot light blend was wrong because it is
calculated for pivot at the edges. The new implementation in theory
works for all `abs(pivot) <= 0.5f`, although we only have -0.5, 0, and
0.5.
- Axis constraint for box cage was only applied when there is translate
flag, now the same logic is applied regardless of the translate flag,
this means when dragging the edge, the scaling in the other axis stays
the same; when dragging the corners, it applies free-form scaling.
- Due to the existence of margin, `data->orig_mouse` does not lie
exactly on the boundary. Using that value to compute the scaling causes
the error to accumulate over distance. The new implementation uses the
original dimension of the object instead, and only uses
`data->orig_mouse` to determine the side of the original cursor relative
to the pivot.
- For circular gizmo with unsigned scaling, the gizmo only follow the
cursor exactly when the cursor stays in the original quadrant, otherwise
it's hard to handle the logic when we should clamp the scaling.
The buttons of enum context menus are of type `UI_BUT_ROW`. They
are part of the set of buttons we create underline shortcuts for in
`ui_menu_block_set_keyaccels`.
But since they weren't handled in `ui_handle_button_activate_by_type`,
pressing the underline shortcuts didn't do anyting in those cases.
Co-authored-by: Leon Schittek <leon.schittek@gmx.net>
Co-authored-by: Brecht Van Lommel <brecht@noreply.localhost>
Pull Request #104433
Currently the passepartout color is hardcoded to black. While a
sensible default for cinema, it may make less sense for other media,
whether video, print, web, etc. It greatly affects viewing conditions
of the image and should be user selectable, much like painting
programs allow.
Pull Request #104486
Don't create caps when using cyclic profile splines with two or fewer
points.
This case wasn't handled, yet, leading to invalid meshes or crashes.
Co-authored-by: Leon Schittek <leon.schittek@gmx.net>
Pull Request #104594
Vulkan has a pluggable memory allocation feature, which allows internal
driver allocations to be done by the client application provided
allocator. Vulkan uses this for more client application allocations
done inside the driver, but can also do it for more internal oriented
allocations.
VK_ALLOCATION_CALLBACKS initializes allocation callbacks for host allocations.
The macro creates a local static variable with the name vk_allocation_callbacks
that can be passed to vulkan API functions that expect
const VkAllocationCallbacks *pAllocator.
When WITH_VULKAN_GUARDEDALLOC=Off the memory allocation implemented
in the vulkan device driver is used for both internal and application
oriented memory operations.
For now this would help during the development of Vulkan backend to
detect hidden memory leaks that are hidden inside the driver part
of the stack. In a later stage we need to measure the overhead and
if this should become the default behavior.
Pull Request #104434
The GPU module has 2 different styles when reading back data from
GPU buffers. The SSBOs used a memcpy to copy the data to a
pre-allocated buffer. IndexBuf/VertBuf gave back a driver/platform
controlled pointer to the memory.
Readback is done for test cases returning mapped pointers is not safe.
For this reason we settled on using the same approach as the SSBO.
Copy the data to a caller pre-allocated buffer.
Reason why this API is currently changed is that the Vulkan API is more
strict on mapping/unmapping buffers that can lead to potential issues
down the road.
Pull Request #104571
Keep using the 3 evaluations dF_branch method for the Displacement output.
The optimized 2 evaluations method used by node_bump is now on its own macro (dF_branch_incomplete).
displacement_bump modifies the normal that nodetree_exec uses, so even with a refactor it wouldn’t be possible to re-use the computation anyway.
Using larger integer types allows for more efficient code, because we
can use the hardware better. Instead of working on individual bytes,
the code can now work on 8 bytes at a time. We don't really benefit
from this immediately but I'm planning to implement some more optimized
bit vector operations for #104629.
Pull Request #104658
Add a test to address the issue raised in #103913, where zero area
triangles could be created from polygons that have co-linear edges
but were not degenerate.
Since USD is no longer statically linked these linker tricks
are no longer needed.
Co-authored-by: Ray Molenkamp <github@lazydodo.com>
Pull Request #104627
When building a node group that's meant to be used directly in the
node editor as well as in the modifier, it's useful to be able to have
some inputs that are only meant for the node editor, like inputs that
only make sense when combined with other nodes.
In the future we might have the ability to only display certain assets
in the modifier and the node editor, but until then this simple solution
allows a bit more customization.
Pull Request #104517
During hair grooming in curves sculpt mode, it is very useful when hair strands
are prevented from intersecting with the surface mesh. Unfortunately, it also
decreases performance significantly so we don't want it to be turned on all the time.
The surface collision is used by the Comb, Pinch and Puff brushes currently.
It can be turned on or off on a per-geometry basis.
The intersection prevention quality of this patch is not perfect yet. This can
be improved over time using a better solver. Overall, perfect collision detection
at the cost of bad performance is not necessary for interactive sculpting,
because the user can fix small mistakes very quickly. Nevertheless, the quality
can probably still be improved significantly without too big slow-downs depending
on the use case. This can be done separately from this patch.
Pull Request #104469
Previously, the node used the "true" normal of every looptri. Now it uses the
"loop normals" which includes e.g. smooth faces and custom normals. The true
normal can still be used on the points by capturing it before the Distribute node.
We do intend to expose the smooth normals separately in geometry nodes as well,
but this is an important first step.
It's also necessary to generate child hair between guide hair strands that don't
have visible artifacts at face boundaries.
For perfect backward compatibility, the node still has a "Legacy Normal" option
in the side bar. Creating the exact same behavior with existing nodes isn't
really possible unfortunately because of the specifics of how the Distribute
node used to compute the normals using looptris.
Pull Request #104414
CustomData layer names should not be written except via the CusomData
api. Therefore use const char * instead of char * when referencing the
layer name.
Pull Request #104585
Avoid computing the non-derivative height twice.
The height is now computed as part of the main function, while the height at x and y offsets are still computed on a separate function.
The differentials are now computed directly at node_bump.
Co-authored-by: Miguel Pozo <pragma37@gmail.com>
Pull Request #104595
This adds a `select_lasso` and a `select_circle` function for the Curves object. It is used in the `view3d_lasso_select` and `view3d_circle_select` operator.
Co-authored-by: Falk David <falkdavid@gmx.de>
Pull Request #104560
This adds a new `select_linked` function that selects all the points
on a curve if there is at least one point already selected.
This also adds a keymap for the operator.
Co-authored-by: Falk David <falkdavid@gmx.de>
Pull Request #104569
Add `contains_group` method in python api for `NodeTree` type, cleanup
`ntreeHasTree` function, reuse `ntreeHasTree` in more place in code.
The algorithm has been changed to not recheck trees by using set.
Performance gains from avoiding already checked node trees:
Based on tests, can say that for large files with a huge number
of trees, the response speed of opening the search menu in the
node editor increased by ~200 times (for really large projects
with 16 individual groups in 6 levels of nesting). Group insert
operations are also accelerated, but this is different in some cases.
Pull Request #104465
This reverts commit aab707ab70.
A different solution to the submodule problem is being considered in #104573.
Revert to the previous behavior that developers are familiar with for now.
This just adds `threading::parallel_for` and `threading::parallel_invoke` in a few
places where it can be added trivially. The run time of the `separate_geometry`
function changes from 830 ms to 413 ms in my test file.
Pull Request #104563
Using callback functions didn't scale well as more arguments are added.
It got very confusing when to pass tehmarguments weren't always used.
Instead use a `FunctionRef` with indices for arguments. Also remove
unused edge arguments to topology mapping functions.
Adds an experimental option under "New Features" in preferences,
which enables visibility of the new Volume Nodes.
Right now this option does nothing but will be used during development.
See #103248
Pull Request #104552
Because of T95965, some attributes are stored as generic attributes
in Mesh but have special handling for the conversion to BMesh.
Expose a function to tell whether certain attribute names are handled
specially in the conversion, and refactor the error checking process
to use it. Also check for generic attributes on the face domain which
wasn't done before.
Author: Hans Goudey
Reviewed By: Joseph Eagar
Co-authored-by: Joseph Eagar <joeedh@gmail.com>
Pull Request #104567
When merging two gpencil layers, if the destination layer had a keyframe
where the source layer did not, strokes of the previous keyframe
in source layer were lost in that frame.
This happened because the merge operator was looping through
frames of the source layer and appending strokes in the
corresponding destination layer, but never completing
other frames than the ones existing in the source layer.
This patch fixes it by first adding in source layer
all frames that are in destination layer.
Co-authored-by: Amelie Fondevilla <amelie.fondevilla@les-fees-speciales.coop>
Pull Request #104558
When the sequencer is empty (i.e., there are no sequences),
we would have the deselect_all variable set to true called
ED_sequencer_deselect_all to select any existing sequences.
Ref !104453
Box-Selecting channels in the dope sheet with click-drag was no longer possible as of Blender 3.2
Due to the removal of tweak events the box select operator was always shadowed by the click operator.
Original Phabricator discussion here: https://archive.blender.org/developer/D17065
Use `WM_operator_flag_only_pass_through_on_press` on click operator to fix it
Co-authored-by: Christoph Lendenfeld <chris.lenden@gmail.com>
Pull Request #104505
(Follow on from D17043)
On AMD Navi2 devices the MetalRT checkbox was not hooked up properly and had no effect. This patch fixes it.
Co-authored-by: Michael Jones <michael_p_jones@apple.com>
Pull Request #104520
- Avoid flooding the output with every match that succeeds.
- Report patterns listed in the manual that don't match anything in
Blender.
- Disable external URL lookups, this is too slow.
Instead use a LOCAL_PREFIX (a local build of the manual)
or skip the test.
Without this, every access to "language" would warn that the enum
value didn't match a value in the enum items.
This made the bl_rna_manual_reference.py test output practically
unusable.
The generator now skips these with a warning, they will need to be
corrected in the user manual.
This caused tests/python/bl_rna_manual_reference.py to fail looking
up URL's.
Move the function for getting the language code associated with the
user manual into a utility function (from the generated
rna_manual_reference.py).
This allows other parts of Blender to create a manual URL based on the
current locale preferences and environment.
Ref !104494
Documented all functions, adding use case and side effects.
Also replace the use of shortened argument name by more meaningful ones.
Renamed `GPU_batch_instbuf_add_ex` and `GPU_batch_vertbuf_add_ex` to remove
the `ex` suffix as they are the main version used (removed the few usage
of the other version).
Renamed `GPU_batch_draw_instanced` to `GPU_batch_draw_instance_range` and
make it consistent with `GPU_batch_draw_range`.
When nodes are copied to the clipboard, they don't need their declaration.
For nodes with dynamic declaration that might depend on the node tree itself,
the declaration could not be build anyway, because the node-clipboard does
not have a node tree.
Pull Request #104432
Add a new node that groups faces inside of boundary edge regions.
This is the opposite action as the existing "Face Group Boundaries"
node. It's also the same as some of the "Initialize Face Sets"
options in sculpt mode.
Discussion in #102962 has favored "Group" for a name for these
sockets rather than "Set", so that is used here.
Pull Request #104428
Currently there's no way to assign a geometry node group from the asset
browser to an object as a modifier without first appending/linking it
manually. This patch adds a drag and drop operator that adds a new
modifier and assigns the dragged tree.
Pull Request #104430
As described in #95966, replace the `ME_EDGEDRAW` flag with a bit
vector in mesh runtime data. Currently the the flag is only ever set
to false for the "optimal display" feature of the subdivision surface
modifier. When creating an "original" mesh in the main data-base,
the flag is always supposed to be true.
The bit vector is now created by the modifier only as necessary, and
is cleared for topology-changing operations. This fixes incorrect
interpolation of the flag as noted in #104376. Generally it isn't
possible to interpolate it through topology-changing operations.
After this, only the seam status needs to be removed from edges before
we can replace them with the generic `int2` type (or something similar)
and reduce memory usage by 1/3.
Related:
- 10131a6f62
- 145839aa42
In the future `BM_ELEM_DRAW` could be removed as well. Currently it is
used and aliased by other defines in some non-obvious ways though.
Pull Request #104417
This adds a `select_box` function for the `Curves` object. It is used in the `view3d_box_select` operator.
It also adds the basic selection tools in the toolbar of Edit Mode.
Authored-by: Falk David <falkdavid@gmx.de>
Pull Request #104411
The required version numbers for various devices was hardcoded in the
UI messages. The result was that every time one of these versions was
bumped, every language team had to update the message in question.
Instead, the version numbers can be extracted, and injected into the
error messages using string formatting so that translation updates
need happen less frequently.
Pull Request #104488
`bAnimContext` had a float property called `yscale_fac` that was used to define the height of the keyframe channels.
However the property was never set, only read so there really is no need to have it in the struct.
Moreover it complicated getting the channel height because `bAnimContext` had to be passed in.
Speaking of getting the channel height. This was done with macros. I ripped them all out and replaced them with function calls.
Originally it was introduced in this patch: https://developer.blender.org/rB095c8dbe6919857ea322b213a1e240161cd7c843
Co-authored-by: Christoph Lendenfeld <chris.lenden@gmail.com>
Pull Request #104500
This is used for most Python release builds and has been reported to
give a modest 5-10% speedup (depending on the workload).
This could be enabled on macOS too but needs to be tested.
Blender was reporting that the GPU_TEXTURE_USAGE_HOST_READ wasn't set.
This is used to indicate that the textures needs to be read back to
CPU. Textures that don't need to be read back can be optimized by the
GPU backend.
Found during investigation of #104282.
- Use bpy.utils.execfile instead of importing then deleting from
sys.modules.
- Add a note for why keeping this cached in memory isn't necessary.
This has the advantage of not interfering with any scripts that import
`rna_manual_reference` as a module.
This allow to bypass all cost associated with shadow mapping.
This can be useful in certain situation, such as opening a scene on a
lower end system or just to gain performance in some situation (lookdev).
The merge with master updated the code to use the new matrix API. This
introduce some regressions.
For sunlights make sure there is enough tilemaps in orthographic mode
to cover the depth range and fix the level offset in perspective.
Implements virtual shadow mapping for EEVEE-Next primary shadow solution.
This technique aims to deliver really high precision shadowing for many
lights while keeping a relatively low cost.
The technique works by splitting each shadows in tiles that are only
allocated & updated on demand by visible surfaces and volumes.
Local lights use cubemap projection with mipmap level of detail to adapt
the resolution to the receiver distance.
Sun lights use clipmap distribution or cascade distribution (depending on
which is better) for selecting the level of detail with the distance to
the camera.
Current maximum shadow precision for local light is about 1 pixel per 0.01
degrees.
For sun light, the maximum resolution is based on the camera far clip
distance which sets the most coarse clipmap.
## Limitation:
Alpha Blended surfaces might not get correct shadowing in some corner
casses. This is to be fixed in another commit.
While resolution is greatly increase, it is still finite. It is virtually
equivalent to one 8K shadow per shadow cube face and per clipmap level.
There is no filtering present for now.
## Parameters:
Shadow Pool Size: In bytes, amount of GPU memory to dedicate to the
shadow pool (is allocated per viewport).
Shadow Scaling: Scale the shadow resolution. Base resolution should
target subpixel accuracy (within the limitation of the technique).
Related to #93220
Related to #104472
The previous change in the .gitmodules made it so the `make update`
rejects to do its thing because it now sees changes in the submodules
and rejected to update, thinking there are unstaged changes.
Ignore the submodule changes, bringing the old behavior closer to
what it was.
The meaning of the ignore option for submodules did change since our
initial Git setup was done: back then it was affecting both diff and
stage families of Git command. Unfortunately, the actual behavior did
violate what documentation was stating (the documentation was stating
that the option only affects diff family of commands). This got fixed
in Git some time after our initial setup and it was the behavior of the
commands changed, not the documentation. This lead to a situation when
we can no longer see that submodules are modified and staged, and it is
very easy to stage the submodules.
For the clarity: diff and status are both "status" family, show and
diff are "diff" family.
Hence this change: since there is no built-in zero-configuration way
of forbidding Git from staging submodules lets make it visible and
clear what the state of submodules is.
We still need to inform people to not stage submodules, for which
we can offer some configuration tips and scripts but doing so is
outside of the scope of this change at it requires some additional
research. Current goal is simple: make it visible and clear what is
going to be committed to Git.
This is a response to an increased frequency of incidents when the
submodules are getting modified and committed without authors even
noticing this (which is also a bit annoying to recover from).
Differential Revision: https://developer.blender.org/D13001
Subdivision surface efficiency relies on caching pre-computed topology
data for evaluation between frames. However, while eed45d2a23
introduced a second GPU subdiv evaluator type, it still only kept
one slot for caching this runtime data per mesh.
The result is that if the mesh is also needed on CPU, for instance
due to a modifier on a different object (e.g. shrinkwrap), the two
evaluators are used at the same time and fight over the single slot.
This causes the topology data to be discarded and recomputed twice
per frame.
Since avoiding duplicate evaluation is a complex task, this fix
simply adds a second separate cache slot for the GPU data, so that
the cost is simply running subdivision twice, not recomputing topology
twice.
To help diagnostics, I also add a message to show when GPU evaluation
is actually used to the modifier panel. Two frame counters are used
to suppress flicker in the UI panel.
Differential Revision: https://developer.blender.org/D17117
Pull Request #104441
The ear clipping method used by polyfill_2d only excluded concave ears
which meant ears exactly co-linear edges created zero area triangles
even when convex ears are available.
While polyfill_2d prioritizes performance over *pretty* results,
there is no need to pick degenerate triangles with other candidates
are available. As noted in code-comments, callers that require higher
quality tessellation should use BLI_polyfill_beautify.
Sockets after the geometry socket were ignored when cycling through
the node's output sockets. If there are multiple geometry sockets, the
behavior could still be refined probably, but this should at least make
basic non-geometry socket cycling work.
Now a single script to generate both links and release notes. It also includes
the issue ID for the LTS releases, so only the release version needs to be
specified.
Pull Request #104402
Minor change to [0], prefer calling em_setup_viewcontext,
even though there is no functional difference at the moment,
if this function ever performs additional operations than assigning
`ViewContext.em`, it would have to be manually in-lined in
`view3d_circle_select_recalc`.
[0]: 430cc9d7bf
Added missing documentation for `draw_cursor_add` and
`draw_cursor_remove` methods for `WindowManager`.
Differential Revision: https://developer.blender.org/D14860
Discard is not always treated as an explicit return and flow control can continue for required derivative calculations. This behaviour is different in Metal vs OpenGL. Adding return after discards ensures consistency in expectation as behaviour is well-defined.
Authored by Apple: Michael Parkin-White
Ref T96261
Reviewed By: fclem
Maniphest Tasks: T96261
Differential Revision: https://developer.blender.org/D17199
Host memory fallback in CUDA and HIP devices is almost identical.
We remove duplicated code and create a shared generic version that
other devices (oneAPI) will be able to use.
Reviewed By: brecht
Differential Revision: https://developer.blender.org/D17173
Straightforward port. I took the oportunity to remove some C vector
functions (ex: copy_v2_v2).
This makes some changes to DRWView to accomodate the alignement
requirements of the float4x4 type.
Although computed in the geometry node, this normal is specific for
hairs is only implemented for Catmull-Rom splines. Questions remain
whether this should be generalized, also a few design ideas are obscure.
{F14115834}
# Disable opencollada when we don't have precompiled libs
option(WITH_OPENCOLLADA"Enable OpenCollada Support (http://www.opencollada.org)"ON)
option(WITH_IO_WAVEFRONT_OBJ"Enable Wavefront-OBJ 3D file format support (*.obj)"ON)
option(WITH_IO_PLY"Enable PLY 3D file format support (*.ply)"ON)
option(WITH_IO_STL"Enable STL 3D file format support (*.stl)"ON)
option(WITH_IO_GPENCIL"Enable grease-pencil file format IO (*.svg, *.pdf)"ON)
@@ -524,7 +524,7 @@ endif()
if(NOTAPPLE)
option(WITH_CYCLES_DEVICE_HIP"Enable Cycles AMD HIP support"ON)
option(WITH_CYCLES_HIP_BINARIES"Build Cycles AMD HIP binaries"OFF)
set(CYCLES_HIP_BINARIES_ARCHgfx1010gfx1011gfx1012gfx1030gfx1031gfx1032gfx1034gfx1035gfx1100gfx1101gfx1102CACHESTRING"AMD HIP architectures to build binaries for")
set(CYCLES_HIP_BINARIES_ARCHgfx900gfx906gfx90cgfx902 gfx1010gfx1011gfx1012gfx1030gfx1031gfx1032gfx1034gfx1035gfx1100gfx1101gfx1102CACHESTRING"AMD HIP architectures to build binaries for")
mark_as_advanced(WITH_CYCLES_DEVICE_HIP)
mark_as_advanced(CYCLES_HIP_BINARIES_ARCH)
endif()
@@ -625,8 +625,10 @@ mark_as_advanced(
# Vulkan
option(WITH_VULKAN_BACKEND"Enable Vulkan as graphics backend (only for development)"OFF)
option(WITH_VULKAN_GUARDEDALLOC"Use guardedalloc for host allocations done inside Vulkan (development option)"OFF)
/* SSE optimization disabled for now on 32 bit, see bug T36316. */
/* SSE optimization disabled for now on 32 bit, see bug #36316. */
# if !(defined(__GNUC__) && (defined(i386) || defined(_M_IX86)))
# define __KERNEL_SSE2__
# define __KERNEL_SSE3__
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.