WIP: Geometry Nodes: Port triangulate node from BMesh to Mesh #112264
No reviewers
Labels
No Label
Interest
Alembic
Interest
Animation & Rigging
Interest
Asset Browser
Interest
Asset Browser Project Overview
Interest
Audio
Interest
Automated Testing
Interest
Blender Asset Bundle
Interest
BlendFile
Interest
Collada
Interest
Compatibility
Interest
Compositing
Interest
Core
Interest
Cycles
Interest
Dependency Graph
Interest
Development Management
Interest
EEVEE
Interest
EEVEE & Viewport
Interest
Freestyle
Interest
Geometry Nodes
Interest
Grease Pencil
Interest
ID Management
Interest
Images & Movies
Interest
Import Export
Interest
Line Art
Interest
Masking
Interest
Metal
Interest
Modeling
Interest
Modifiers
Interest
Motion Tracking
Interest
Nodes & Physics
Interest
OpenGL
Interest
Overlay
Interest
Overrides
Interest
Performance
Interest
Physics
Interest
Pipeline, Assets & IO
Interest
Platforms, Builds & Tests
Interest
Python API
Interest
Render & Cycles
Interest
Render Pipeline
Interest
Sculpt, Paint & Texture
Interest
Text Editor
Interest
Translations
Interest
Triaging
Interest
Undo
Interest
USD
Interest
User Interface
Interest
UV Editing
Interest
VFX & Video
Interest
Video Sequencer
Interest
Virtual Reality
Interest
Vulkan
Interest
Wayland
Interest
Workbench
Interest: X11
Legacy
Blender 2.8 Project
Legacy
Milestone 1: Basic, Local Asset Browser
Legacy
OpenGL Error
Meta
Good First Issue
Meta
Papercut
Meta
Retrospective
Meta
Security
Module
Animation & Rigging
Module
Core
Module
Development Management
Module
EEVEE & Viewport
Module
Grease Pencil
Module
Modeling
Module
Nodes & Physics
Module
Pipeline, Assets & IO
Module
Platforms, Builds & Tests
Module
Python API
Module
Render & Cycles
Module
Sculpt, Paint & Texture
Module
Triaging
Module
User Interface
Module
VFX & Video
Platform
FreeBSD
Platform
Linux
Platform
macOS
Platform
Windows
Priority
High
Priority
Low
Priority
Normal
Priority
Unbreak Now!
Status
Archived
Status
Confirmed
Status
Duplicate
Status
Needs Info from Developers
Status
Needs Information from User
Status
Needs Triage
Status
Resolved
Type
Bug
Type
Design
Type
Known Issue
Type
Patch
Type
Report
Type
To Do
No Milestone
No project
No Assignees
4 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: blender/blender#112264
Loading…
Reference in New Issue
No description provided.
Delete Branch "HooglyBoogly/blender:mesh-triangulate"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Add a Mesh implementation of triangulation, which is currently just
implemented for BMesh. The main benefit of this is performance and
decreased memory usage. The benefit is especially large because the
node currently converts to BMesh, triangulates, and then converts back.
But the BMesh implementation is entirely single threaded, so it will
always be much slower.
The new implementation uses the principle of "never just process a
single element at a time" but it also tries to avoid processing too
many elements at once, to decrease the size of temporary buffers.
Practically that means the work is organized into chunks of selected
faces, but within each chunk, each task is done in a separate loop.
Arguably I went a bit far with some optimizations, and some of the
complexity isn't necessary, but I hope everything is clear anyway.
Unlike some other Mesh ports like the extrude node or the split edges
code, this generates a new mesh. I still go back and forth on that
aspect, but reusing the same mesh would have required reallocating
face attributes from scratch anyway. Implicit sharing is used to
avoid copying vertex attributes though.
The result mesh is reorganized a bit. Unselected face data comes first,
then selected triangles, then triangulated NGons, then triangulated
quads. This makes attribute interpolation and internal calculations
more efficient.
The "Minimum Vertices" socket is replaced with versioning. In the new
implementation it would have an impact on code complexity, and for a
builtin "atomic" node it makes more sense as part of the selection.
The performance difference depends on the number of CPU threads, the
number of attributes, and the selection size. As all of those numbers
go up, the benefit will grow. The "modes" also affect the performance,
obviously.
With a Ryzen 7950x, I tested performance in a few situations (runtime in ms):
In follow-up commits, I'll move other areas to use mesh triangulation
instead of BMesh. This is the last geometry node using BMesh besides
the Ico Sphere primitive.
TODO
Resolve face deduplication
New triangles can be created that are the same as triangles that already exist.
They need to be deduplicated or otherwise not created. This work can be skipped
when the input mesh doesn't have any triangles. Ideas:
Add edge deduplication
Add a topology cache to meshes that allows us to skip this.
Test for the versioning code:

Three new regression tests are attached below.
Was intrigued by the PR and left some comments :) Nice improvement!
@ -177,0 +181,4 @@const float v4[3],const bool lock_degenerate){/* not a loop (only to be able to break out) */Am I missing something here, or could you just
return FLT_MAXinstead of thebreaks and the loop? And since at the end of the loop body, it returns anyway, the final return is no longer needed.Yeah, I have no clue. This code is moved from the BMesh module so it can be shared. I'd rather not change it in this commit though, since I'm just moving it.
Makes sense if you're just moving it.
@ -0,0 +300,4 @@const OffsetIndices<int> faces,const int edges_start,const int corner_map_offset,MutableSpan<int> corner_map,These should probably prefixed with
r_@ -0,0 +476,4 @@});}std::optional<Mesh *> mesh_triangulate(Why return an optional pointer, when you can just return
nullptr?A couple other mesh operations do this, since they sometimes need to differentiate between the two. For example, "copy mesh selection" uses it to return a "no changes to input mesh".
optionalisn't necessary here I suppose, I can remove it.Either way, there needs to be some comment for what the return value means. The
optionaldoesn't help me here, definitely not on its own.I started with some testing, and noticed that beauty mode gave different results:
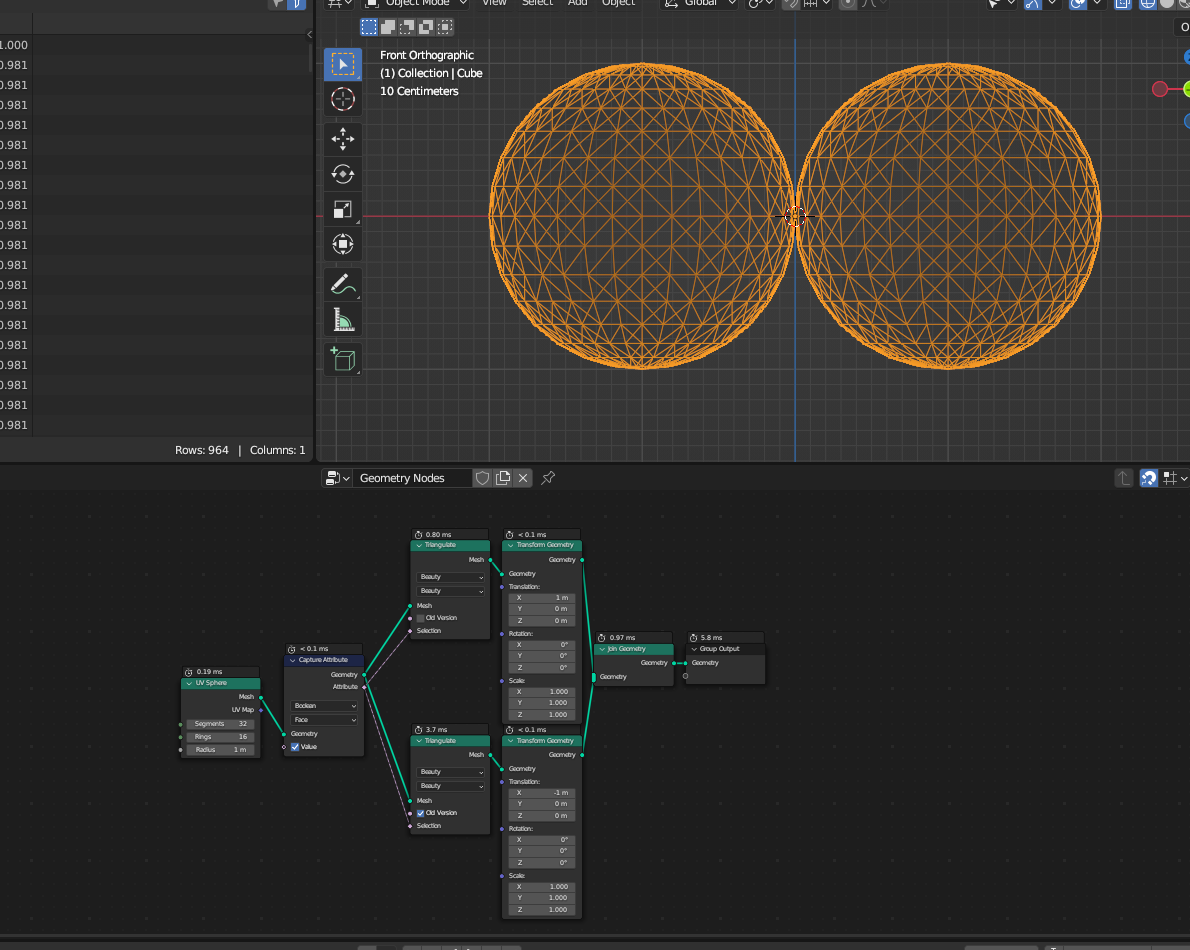
I don't think that this change of output is "expected".
The reason the node looks slightly different is that for easier testing I added some code to be able to access both the old and new version of the node:
Didn't read everything yet.
Can you maybe add some regression tests for the triangulate node that don't break by this patch? Think it should be possible to use the sorting of the Points to Curve node to get rid of the index dependence. Ideally, the versioning code is tested by those tests as well.
I wonder if there is a reason for sometimes using
Ngonsand sometimesngons.@ -0,0 +14,4 @@namespace blender::geometry {enum class TriangulateNGonMode {Would be nice to have a short description for what these mean in practice.
Add some here, but the "beauty" and "polyfill" algorithms remain a bit vague to me, they're just in functions called by the old and new code.
@ -0,0 +30,4 @@std::optional<Mesh *> mesh_triangulate(const Mesh &src_mesh,const IndexMask &selection,const TriangulateNGonMode ngon_mode,No need for
const.@ -0,0 +518,4 @@const OffsetIndices edges_by_ngon = calc_edges_by_ngon(src_faces, ngons, edge_offset_data);/* Unselected faces are moved to the beginning of the new mesh. */const IndexRange unselected_range(0, unselected.size());The naming of these variables can probably be unified since they are conceptually very similar.
@ -0,0 +535,4 @@/* All newly created edges (from Ngons and quads). */const IndexRange inner_edges(ngon_edges.start(), ngon_edges.size() + quad_edges.size());/* Create a mesh with no face corners, since we don't know how many there will be yet. */Why is that not known yet? Can't that be easily computed based on the information above?
We know the total number of corners from the final NGon triangles, but we didn't count the number of corners in the original NGons. Maybe there's a way to go quickly calculate it from the information we have anyway, not sure though.
This pattern of creating a mesh with no attributes is also helpful since it allows using implicit sharing when copying vertex attributes. (The same thing is done in
mesh_copy_selection.cc).@ -97,0 +62,4 @@std::optional<Mesh *> mesh = geometry::mesh_triangulate(*src_mesh,selection,geometry::TriangulateNGonMode(ngon_method),Looks like this should static-assert that the values are actually all the same and/or there should be a comment on both enums that they need to be kept in sync, or we just get rid of
GeometryNodeTriangulateNGons.Thanks! Found the issue. Source was confusing variable names in the BMesh code. Added a comment about that.
I added regression tests to the PR. But I didn't get to the index independence, or regression tests for the versioning.
Hmm, I thought I was consistent about saying "NGon" in comments and "ngon" as variable names.
Edge attributes are currently propagated differently in
mainvs. this patch.Geometry Nodes: Port triangulate node from BMesh to Meshto Geometry Nodes: Port triangulate node from BMesh to MeshGeometry Nodes: Port triangulate node from BMesh to Meshto WIP: Geometry Nodes: Port triangulate node from BMesh to Mesh@ -180,3 +179,1 @@* \note The result may be an empty span.*/static MutableSpan<int> get_orig_index_layer(Mesh &mesh, const eAttrDomain domain)static std::optional<MutableSpan<int>> get_orig_index_layer(Mesh &mesh, const eAttrDomain domain)Are the changes to the
node_geo_extrude_mesh.ccintentional? Seems strange to include them in this PR.Yeah, that's just something I noticed when trying to share code between multiple nodes. I'll commit a bunch of the changes here separately before requesting review again. Thanks for looking :)
Checkout
From your project repository, check out a new branch and test the changes.